|
Mogan
Gh.L., Butnariu S.L., Buzdugan I.D.
Organe de mașini. Lucrări de laborator. Universitatea Transilvania din Brașov
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
1. PRELUCRAREA ŞI ANALIZA STATISTICĂ A
DATELOR EXPERIMENTALE |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2.1 ASPECTE GENERALE (Go
to 2.1) 2.2 MĂRIMI FIZICE MĂSURABILE (Go to 2.2) 2.2.1 Mărimi fizice
variabile măsurate (Go to 2.2.1) 2.2.1.1 Mărimi fizice monovariabile (Go
to 2.2.1.1) 2.2.1.2 Mărimi fizice bivariabile (Go
to 2.2.1.2) 2.2.1.3 Mărimi fizice multivariabile (Go
to 2.2.1.3) 2.2.2 Reprezentări (vizualizări) a datelor (variabilelor)
obținute prin măsurare (Go to 2.2.2) 2.2.2.1 Reprezentări
tabelare de tip Excel (Go to 2.2.2.1) 2.2.2.2 Reprezentări grafice
(Go to 2.2.2.2) 2.3 MĂSURAREA MĂRIMILOR FIZICE. ERORI DE MĂSURARE
(Go to 2.3) 2.3.1 Metode de măsurare (Go to 2.3.1) 2.3.2 Erori și
precizia de măsurare (Go to 2.3.2) 2.4 ELEMENTE DE TEORIA PRBABILITĂȚILOR
APLICATE ÎN STATISTICĂ (Go to
2.4) 2.4.1 Aspecte generale (Go
to 2.4.1) 2.4.2 Distribuții (repartiții, legi) probabilistice
teoretice (Go to 2.4.2) 2.4.2.1 Distribuția
normală (Gauss) (Go to 2.4.2.1) 2.4.2.2 Distribuția
normală standard (Go to 2.4.2.2) 2.4.2.3 Distribuția t
(Student) (Go to 2.4.2.3) 2.4.2.4 Distribuția F
(Fischer) (Go to 2.4.2.4) 2.5 PRELUCRAREA STATISTICĂ A DATELOR
EXPERIMENTALE (Go to 2.5) 2.5.1 Aspecte generale (Go
to 2.5.1) 2.5.2 Variabile statistice (Go to 2.5.2) 2.5.3 Elemente de statistică
descriptivă (Go to 2.5.3) 2.5.3.1 Indicatori statistici descriptvi, generalități (Go to 2.5.3.1) 2.5.3.2 Indicatori statistici ai tendinței centrale (de medie): Media, Mediana,
Modul (Go to 2.5.3.2) 2.5.3.3 Indicatori de poziționare (localizare):
Maximul/Minimul, Amplitudininea (Range), Caurtile,
Percentile (Go to 2.5.3.3) 2.5.3.4 Indicatori
statistici ai formei
distribuției: Asimetria (Skewness), Boltirea (Kurtosis) (Go to 2.5.3.4) 2.5.3.5 Indicatori statistici de dipsersie (împrăștiere): Dispersia
(Variance), Abaterea standard (Standard Deviation), Coieficientul de
variație, Eroarea standard (Go to 2.5.3.5) 2.5.3.6 Indicatori
statistici de probabilitate: Transformata z, Densitatea de probabilitate
(probabilitatea cumulată), Scorul z, Intervalul de încredere (Go
to 2.5.3.6) 2.5.3.7 Indicatori statistici de corelare (asociere) a două
variabile: Coeficientul de covarianță, Coeficențul de
corelație, Matricea de covarianță (Go to 2.5.7.7) 2.5.4 Analize statistice
descriptive (Go
to 2.5.4) 2.5.4.1 Analize statistice descriptive bazate pe reprezentări
grafice ale frecvențelor (Go to 2.5.4.1) 2.5.4.2 Analize statistice descriptive bazate pe reprezentări
grafice de tip boxplot (Go
to 2.5.4.2) 2.5.4.3 Analize statistice descriptive bazate pe reprezentări
grafice a distribuției (repartiției) datelor (Go
to 2.5.4.3) 2.5.4.4 Analize statistice descriptive bazate pe valori ale
indicatorilor statistici (Go to 2.5.4.4) 2.5.5 Analize statistice inferenţiale (deductive) (Go
to 2.5.5) 2.5.5.1 Aspecte generale (Go to 2.5.5.1) 2.5.5.2 Modelarea
problemelor de statistică inferențială (Go to 2.5.5.2) 2.5.5.3 Alegerea tipului testului statistic (Go to 2.5.5.3)
2.5.5.4 Descrierea (formularea) problemei
statistice (Go to 2.5.5.4)
2.5.5.5 Algoritm general de rezolvare a testelor
statistice de decizie (Go to 2.5.5.5)
2.5.5.6 Analize (teste) statistice de decizie/estimare (Go to 2.5.5.6)
2.5.5.6.1 Aplicație testul z de medie pentru o variabilă (Go to 2.5.5.6.1)
2.5.5.6.2 Aplicație testul t de medie pentru o variabilă (Go to 2.5.5.6.2) 2.5.5.6.3 Aplicație t-test de medie pentru două variabile
pereche (dependente) (Go to 2.5.5.6.3) 2.5.5.6.4 Aplicație t-test de medie pentru două variabile
nepereche (independente) cu dispersii egale (Go to 2.5.5.6.4) 2.5.5.6.5 Aplicație t-test de medie pentru două variabile nepereche
(independente) cu dispersii inegale (Go to 2.5.5.6.5) 2.5.5.6.6 Aplicație testul F de dispersie
pentru două variabile (Go
to 2.5.5.6.6) 2.5.5.6.7 Aplicație ANOVA cu un singur factor (one-way ANOVA, Single Factor)
2.5.5.6.8 Aplicație testul ANOVA cu doi factori fără replicație (ANOVA:
Two-Factor Without Replication) (Go to 2.5.5.6.8) 2.5.5.6.9 Aplicație testul ANOVA cu doi factori cu replicație (ANOVA: Two-Factor with
Replication) (Go to 2.5.5.6.9)
2.5.5.7 Analize
inferențiale de corelare și regresie (Go to 2.5.7) 2.5.5.7.1 Aplicație de
analiza corelației a două variabile (Go to 2.5.7.1) 2.5.5.7.2 Aplicație de
analiza regresiei liniare simplă (Go to 2.5.7.2) 2.6 BAZELE STUDIILOR
EXPERIMENTALE PRIN MĂSURĂTORI (Go to 2.6) 2.6.1 Aspecte generale (Go to 2.6.1) 2.6.2 Planificarea (proiectarea)
experimentelor unifactoriale (Go to 2.6.2) 2.6.2.1 Definirea și enunțul problemei (Go to 2.6.2.1) 2.6.2.2 Scopul și obiectivele cercetării experimentale (Go to 2.6.2.2) 2.6.2.3 Stabilirea populației țintă (de interes) și
a ipotezelor statistice (Go to 2.6.2.3) 2.6.2.4 Determinarea volumului (mărimii) eșantionului (Go to 2.6.2.4) 2.6.3 Realizarea
experimentelor, colectarea şi/sau achiziţia datelor (Go to 2.6.3) 2.6.3.1 Colectarea datelor prin chestionare (online) (Go to 2.6.3.1) 2.6.3.2 Achiziţia automată a datelor (Go to 2.6.3.2) 2.6.4 Prelucrarea statistică
şi analiza datelor (Go to 2.6.4) 2.6.4.1 Analiza primară a datelor (Go to 2.6.4.1) 2.6.4.2 Prelucrarea statistică și analiza
finală (Go to 2.6.4.2) 2.6.5 Interpretarea
rezultatelor şi elaborarea concluziilor (Go to 2.6.5) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2.1 ASPECTE GENERALE Cercetarea ştiinţifică experimentală ca investigaţie practică urmăreşte, pe de-o parte, descoperirea şi descrierea de noi cunoştinţe (fenomene, procese, legi etc.) şi, pe de altă parte, verificarea unor cunoştinţe obţinute pe alte căi (teoretice, teoretico-experimentale, empirice etc.). Cercetările experimentale de verificare a unor legităţi ca parte importantă a cercetării ştiinţifice au la bază măsurători repetate ale unuia sau mai multor parametri prin care se pot studia variaţiiile şi influenţele unuia sau mai multor factori asupra unui proces definit teoretic anterior. Pentru o bună validare dar şi pentru o bună eficenţă economică numărul măsurătorilor, numit eşantion, este limitat la valori, de obicei, determinate de tipul paramatrului măsurat, instalaţia experimentală, metodoligia de prelucrare a rezultatelor etc. Scopul cercetărilor experimentale de verificare, bazate pe rezultate obţinute pentru unul sau mai multe eşantione (numere limitate de măsurători), este de generalizare, prin prelucrări statistice, a rezultatelor obţinute pentru acesta la toate valorile posibile (de obicei, infinite), validând astfel modelul studiat. În funcţie de numărul de factori de influenţă se pot utiliza diverse metode probabilistic-statistice pentru prelucrarea datelor experimentale, care permit analize şi interpretări statistice precise şi deci sintetizarea unor concluzii de validare riguroase. 2.2 MĂRIMI FIZICE
MĂSURABILE În inginerie mărimile
asociate unor parametri fizici (ex. masa, presiunea, forţa etc.) pot fi
evaluate şi exprimate numeric, în urma măsurătorilor (experimentelor), de
obicei, prin variabile cu diferite valori, care
nu se cunosc dinainte. Mărimile măsurabile, ca manifestări ale
proprietăţilor unui obiect sau proces fizic, în funcţie de modul de
reprezentare pot fi scalare: scalare, caracterizate de un singur număr; vectoriale,
caracterizate de modul, direcţie şi sens; tensoriale exprimate prin
matrice și în funcţie de varaţia în timp: constante şi variabile
(determinist sau aleatorii) 2.2.1 Mărimi
fizice variabile măsurate În cadrul cercetărilor
experimentale se constată că valorile numerice măsurate pot fi diferite chiar
dacă rămân nemodificate condiţiile de desfăşurare ale măsurătorilor. Astfel,
descrierea unui set de date obținute prin măsurători se face cu variabila aleatoare
ale cărei valori caracterizează mărimea măsurată privită din două puncte de
vedere: cantitativ, prin valoarea numerică și calitativ,
prin frecvenţa de apariţie a valorii numerice în setul de date. Dacă
valorile numerice ale unui set de date aparţin mulţimii numerelor întregi
atunci se defineşte o variabilă aleatoare discretă, iar în cazul în
care valorile sunt reale se defineşte o variabilă aleatoare continuă. 2.2.1.1 Mărimi fizice monovariabile În urma măsurării, în
condiții practic identice, a unei mărimi fizice, de obicei, independentă
(neinfluență de alte mărimi fizice), se poate obține un set de
valori {x1, x2 … xn,
… xi}, deseori repetitive, care formează o monovariabilă, x = {x1, x2 … xn} cu n valori. 2.2.1.2 Mărimi fizice bivariabile În cazul obținerii
prin măsurare a două variabile x = {x1,
x2 … xn} și
y = {y1, y2 … yn} se pune
problema corelării datelor
obţinute în vederea stabilirii
unei dependenţe matematice între valorile măsurate
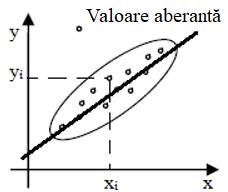
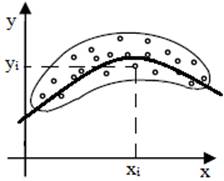
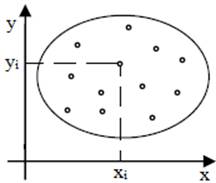
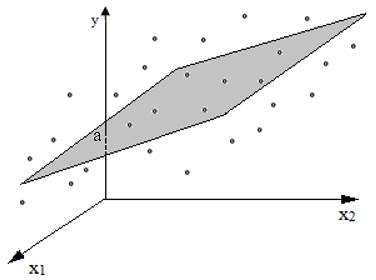
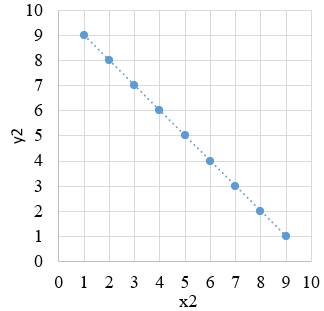
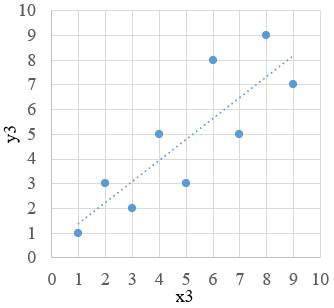
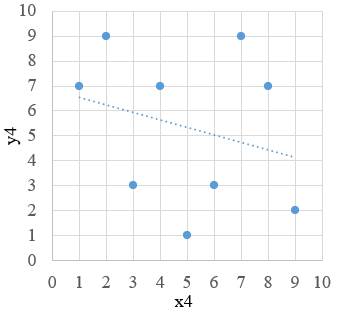
bazată pe o funcţie, y = f(x). Diagrama de împrăştiere a perechilor (xi, yi)
într-un sistem de coordonatele x şi y (fig. 2.1) indică, în funcţie de forma
norului de puncte, tipul relaţiei (funcţiei) matematice dintre variabile care
poate fi, liniară (funcţie polinomială de gradul I, fig. 2.1,a) sau
neliniară curbilinie (fig.
2.1,b): (funcţie polinomială de gradul II (parabolă), exponenţială,
logaritmică, hiperbolă etc.). Dacă în urma analizei vizuale și/sau
statistice nu se distinge nicio tendinţă se apreciază că variabilele nu
sunt corelate (fig. 2.1,c). Gruparea
datelor experimentale reprezentate pe diagrama de împrăștiere
(dispersie) indică, pe lângă posibilitatea aprecierii tipului (formei)
funcţiei, şi valorile eronate (aberante, fig. 2.1,a), ce diferă mult
de celelalte puncte; pentru diminuarea erorilor aceste valori este bine să
fie excluse din prelucrarea ulterioară a datelor experimentale.
a b c Fig. 2.1 Diagrame de împrăștiere a valorilor
seturilor de date: a – liniară; b – curbilinie; c – necorelate Din punct de vedere al abordării
cercetării experimentale pot fi trei cazuri. Primul caz, presupune verificarea
unei funcţii cunoscută teoretic, asociată unei legi fizice. În al doilea caz,
nu se cunoaște, nici chiar, forma (tipul) dependentei f(x) şi prin metode
statistice se realizează corelarea datelor prin estimarea unor dependente tipice
din punct de vedere matematic (polinom, putere, exponențială,
logaritmică etc.) uramată de testarea statistică a acestora. Astfel,
se obțin relaţii empirice, bazate în totalitate pe analiza
statistică a datelor experimentale. În cel de-al treilea caz, pornind de la o
funcție asociată unei legi fizice cu parametri necunoscuți ale
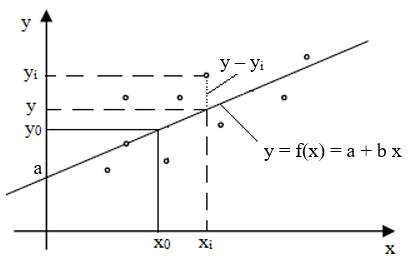
căror valori se determină prin teste statistice, se obțin funcții semi-empirice. Deoarece, valorile obţinute prin măsurare, din cauza erorilor de măsurare întâmplătoare, nu se află pe o linie predefinită (punctele sunt împrăștiate), pentru perechile de valori (xi, yi), i=1…n, se urmăreşte studierea asocierii şi relaţiei dintre acestea. Asocierea valorilor celor două variabile presupune estimarea intensităţii legăturii dintre acestea (mărimile măsurate) pentru găsirea unei relaţii (funcții) matematice care să exprime variabila dependentă (y) în funcție de variabila independentă (x). Cuantificarea intensităţii unei legături dintre cele două variabile, de obicei, prin determinarea coeficientului de corelație (v.subcap.2.5.3.7). Cea mai utilizată tehnică de determinare a unei relații (funcții) dintre valorile măsurate este regresia care presupune determinarea parametrilor unei linii (drepte sau curbe) care unește “cel mai bine” datele reprezentate prin puncte; pentru aceasta sunt folosite, în special, în studii statistice de estimare și predicţie (v.subcap.2.5.5.7.2). Regresia liniară simplă (cu două variabile, x și y) are
la bază o relație polinomială de
gradul întâi (fig. 2.2) între cele două variabile, una independentă
(x) și alta dependentă (y). Dreapta de regresie ca cea mai simplă
dependenţă matematică a valorii prezisă (estimată) a variabilei
dependente y de variabilă independentă x poate fi definită sub forma
canonică, y = f(x) = a + b x,
în care, a este termenul liber (ordonata
la origine, valoarea pentru x = 0) și b coeficientul de regresie (panta dreptei,
coeficientul unghiular). Valorile pozitive ale
pantei b indică
faptul că dreapta se înclină în sus cu creşterea variabilei independente x
(legătura între variabile este pozitivă, directă), iar valorile negative ale
acesteia indică faptul că linia se înclină spre în jos (legătura între
variabile este negativă, inversă). Dacă, b = 0, nu există legătură între variabile.
Fig. 2.2 Regresia lniară simplă Pentru a determina linia de regresie „cea mai bună” se utilizează,
frecvent, metoda celor mai mici pătrate (Legendre, 1806) care
presupune minimizarea sumei pătratelor distanţelor, y – yi (erori
sau reziduuri), S = Pentru ca S să fie minimă, derivatele de ordinul întâi ale acesteia, în raport cu necunoscutele a şi b, egalate cu zero, formează un sistem algebric liniar cu soluţia unică, a = b = Deși regresia
liniară se poate realiza și manual, calculele sunt efectuate mult mai
ușor dacă se utilizează pachete
software specializate, dintre care, frecvent, este utilizat Microsoft
Excel (v.Ghid.Ap.2.21 ). Indiferent de gradul de
împrăştiere al punctelor totdeauna se poate găsi o dreaptă de regresie
care uneori nu estimează cu precizie variabilele măsurate şi deci, după obţinerea celor doi parametri, a
şi b, este necesar ca funcţia de regresie liniara să fie verificată prin teste statistice de
semnificaţie la nivel global și, inclusiv, la nivel de parametrii
acesteia (v.subcap.2.5.5.7.2). Astfel considerând funcţia de regresie a priori valabilă,
se vor aprecia statistic valorile parametrilor (a şi b) care se abat mai mult
sau mai puțin de la valorile prezise, cu o probabilitae impusă.
Dreapta de regresie se poate utiliza ca bază
pentru predicţia (estimarea) valorilor variabilei dependente. Astfel, pentru valoarea x0, valoarea prognozată (estimată)
pentru y este y0, ordonata de pe dreapta de
regresie (fig. 2.2). 2.2.1.3 Mărimi fizice multivariabile Scopul regresiei multiple este de a determina o
relaţia de depentență dintre o variabilă dependentă și două sau mai
multe seturi de variabile independente. În cazul cel mai simplu, cu două
variabile independente, relația de dependență este o extensie a
regresiei simple, numită regresie biliniară. În fig. 2.3 se prezintă
diagrama de împrăştiere asociată funcţiei de regresie cu o variabilă
dependentă y şi două seturi de
variabile independente x1 şi x2. Funcţia de regresie
multiplă are la bază
relația, y = a + b1 x1 + … bi xi +
… bp xp, în care, x1, x2,
… xp sunt seturile de variabile independente; a – termenul liber,
dependent de factorii neincluşi în model considerat constant; bi
(i = 1…p), coeficienţi parţiali de regresie asociaţi seturilor variabilelor
dependente care arată cu câte unităţi se modifică variabila dependentă la
modificarea cu o unitate a variabilei
i iar celelalte variabile sunt menţinute constante.
Fig. 2.3 Regresia biliniară 2.2.2 Reprezentări (vizualizări) a datelor (variabilelor) obținute prin
măsurare În
vederea organizării și sistematizării datelor pentru prelucrarea
statistică, pentru a fi mai ușor de interpretat ulterior, se generează
tabele și grafice care pot sta la baza studiilor ulterioare. Dintre
pachetele software de prelucrare a datelor, cu precădere, tabelar se remarcă,
prin generalitate, simplitate și eficacitate pachetul Microsoft Excel care poate fi folosit
și pentru prelucrarea statistică a datelor experimentale (v.Ghid.Excel.01).
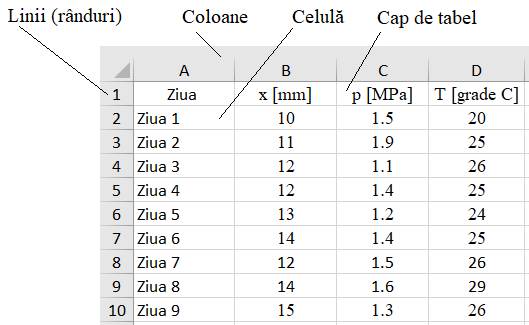
2.2.2.1 Reprezentări tabelare de tip Excel Un tabel Excel este compus din
mai multe celule organizate pe linii și coloane (fig. 2.4). Fiecare
celulă se poate localiza prin intermediul unei etichete compusă din codul
coloanei (o literă a alfabetului de la A la Z) și al liniei (numărul,
1,2,3…), de ex. celula A7, B3, D9 etc. Conținutul unei celule se poate
edita și/sau modifica direct prin introducerea unei date, sau prin
execuția unei funcții predefinită.
Fig. 2.4 Tabel Excel În general, un tablel trebuie să conțină denumirile liniilor și capul de
tabel cu precizarea denumirii mărimilor fizice și a unităților de
măsură ale acestora. În vederea prelucrărilor statistice, seturile de
date obținute prin măsurători, de obicei, conțin valori aleatorii
care pot fi repetabile, sunt organizate tabular ca diverse șiruri de
valori: crescătoare sau descrescătoare, pe grupe (intervale, clase) etc. În vederea interpretării
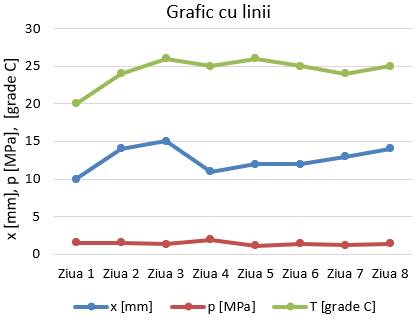
datelor obținute prin măsurători repetate (aleatorii), deosebit de utile
sunt reprezentările grafice: cu puncte
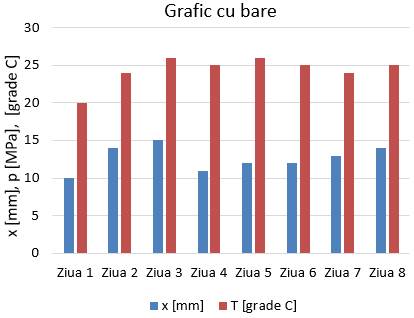
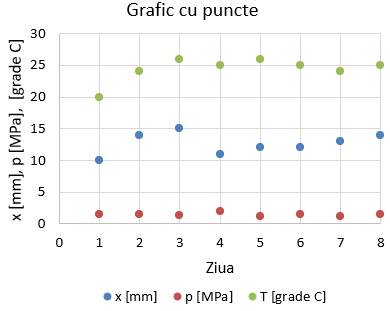
(scatter), cu bare, linii, histograme, boxploturi etc. Un grafic, pentru lizibilitate sporită, trebuie să
conțină: titlu, legendă, denumirea axelor, unitățile de măsură
asociate mărimilor fizice etc. Grafice
cu bare (fig. 2.5,a) prezintă
datele cu ajutorul unor linii (bare), orizontale sau verticale, cu lungimi
diferite. Grafice
cu puncte și/sau cu linii (fig. 2.5,b,c) prezintă datele cu ajutorul unor puncte
și/sau cu linii care le conectează. Grafice
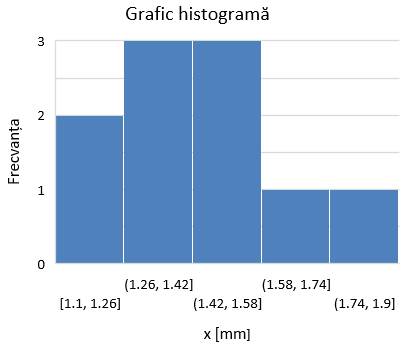
de tip histograma (fig. 2.5,d) utilizează blocuri verticale cu diverse
lungimi cărora li se asociază mărimi omogene (de ex.frecvențele) cu valoril cuprinse în diverse grupuri
(intervale, clase); aceste grafice sunt folosite frecvent pentru prelucrări
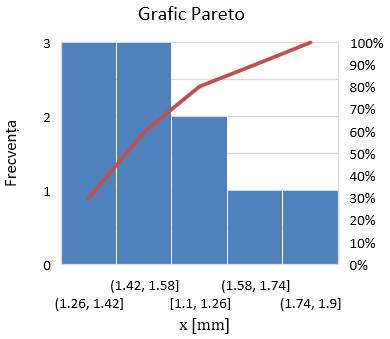
statistice. Graficele Pareto (histogramă sortată, fig. 2.5,e) conțin coloane
sortate în ordine descendentă a unor mărimi omogene (de ex. frecvențe)
cu valori cuprinse în diverse grupuri (intervale, clase) și o linie care reprezintă
variația mărimii cumulată (de obicei, în %); aceste grafice
evidențiază cele mai frecvente valori dintr-un set de date și sunt
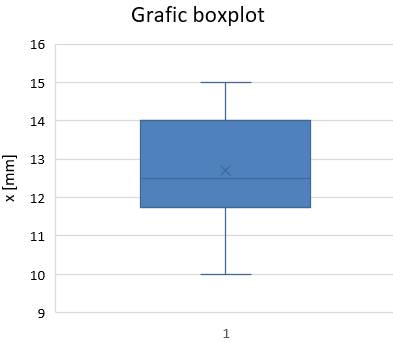
folosite, cu precădere, pentru analize de calitatea produselor/proceselor. Graficele boxplot (fig. 2.5,d) reprezintă datele prin intermediul unui simbol grafic care se descrie prin intermediul unor parametri cu semnificații statistice (v.subcap.2.5.4.2)
2.3 MĂSURAREA MĂRIMILOR
FIZICE. ERORI DE MĂSURARE 2.3.1 Metode de măsurare Măsurarea, în inginerie, este procesul de determinare experimental a valorilor unor mărimi fizice (parametri) asociată unui fenomen, obiect sau proces (sistem) fizic. Aceasta bazat pe pincipii, metode și mijloace specifice are scopul determinării unor valori ale mărimii măsurate apropiate cât mai mult de valoarea reală a acesteia. Metodele de măsurare, după modul de obținere a valoilor mărimii fizice, pot fi directe, când valoarea măsurată se compară cu unitatea de măsură (etalon) sau indirecte, prin care se obține o mărime necunoscută (y) având la bază mai multe valori măsurate direct (x1, x2, x3 …) considerate interdependente printr-o relație dată (y = f(x1, x2, x3 …)); în acest fel se determină o valoare ca efect al unor mărimi măsurate (de ex. determinarea temperaturii ca efect al modificării rezistenței electrice). Pe de altă parte, după tipul datelor achiziționate, metodele de măsurare pot fi pasive, când datele achiziționate sunt mărimi statice (constante în timp) sau de echilibru (de ex. temperatura unui corp), sau active, ce determină mărimi dinamice (variable în timp) ca răspunsuri ale unui sistem (de ex. amplitudinile și frecvențele vibrațiilor unui sistem mecanic ca urmare a excitației cu oscilații periodice); metodele active, deoarece, permit verificarea, modelarea și validarea sistemelor dinamice, sunt numite și de identificare. 2.3.2 Erori și
precizia de măsurare Valorile de măsurare, indiferent cât de riguros ar fi obținute, sunt afectate de erori sau incertitudini, ale căror cauze pot fi legate de: metoda de măsurare, sensibilitatea instrumentelor de măsură, caracteristicile mediului ambiant, performanțele biologice ale operatorului, elementul/sistemul supus măsurării etc. Abilitatea cercetătorului de a evalua erorile şi/sau incertitudinile cu scopul de a le minimiza este esenţială în cercetarea ştiinţifică. Se cunoaşte faptul că
dacă o mărime se măsoară de mai multe ori, de fiecare dată se obţine o altă
valoare chiar dacă măsurătorile se desfăşoară în aceleaşi condiţii, de către
acelaşi operator şi cu aceleași instrumente. Cauza acestor neconcordanţe
este indusă de erorile de măsurare care fac ca valoarea adevărată
(reală) a mărimii măsurate să nu poată fi determinată. Astfel, în practică,
se caută să se determine o valoare cât mai apropiată de aceasta cu un prag
(nivel) mai mare sau mai mic de apropiere (de obicei, evaluat statistic) în
funcţie de scopul experimentelor. Apropierea mărimii determinată prin
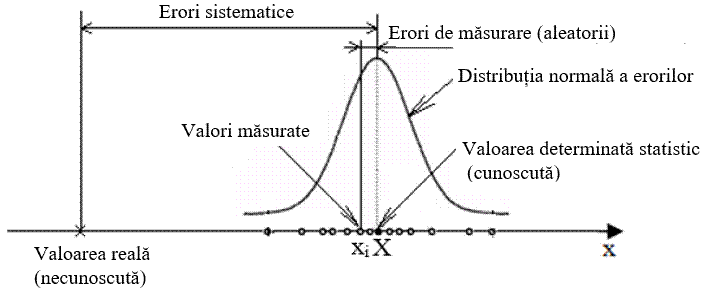
măsurare de valoarea adevărată (reală, necunoscută) se apreciază global prin precizia măsurătorii. Există două mari grupe de erori de
măsurare: sistematice și
accidentale (întâmplătoare). Erorile sistematice apar din cauza reglărilor sau etalonărilor incorecte ale aparatelor de măsură, abaterilor asociate operatorului (de ex. de paralaxă) şi/sau a caracteristicilor mediului în care se fac măsurătorile (temperatura, umiditatea, altitudinea etc.). Aceste erori rămân constante atât ca valoare cât şi ca semn pentru măsurări repetate în condiţii identice. Diminuarea efectelor acestor erori asupra rezultatului se face prin calibrări și/sau corecţii care presupun însumarea unei constante sau înmulţirea cu un factor constant a rezultatelor măsurării. Pentru prelucrarea statistică nu se iau în considerare erorile sistematice, de obicei, acestea fiind corectate, preliminar. Astfel, se impune la începerea experimentelor o verificare atentă a stării aparatelor, a condiţiilor de lucru și, dacă este cazul, chiar a unor de calibrări. Erorile întâmplătoare (aleatorii, accidentale, statistice) apar la măsurări repetate în condiţii cvasiidentice (efectuate de acelaşi experimentator, în aceleaşi condiţii şi cu aceleaşi aparate) ale aceleiași mărimi care variază imprevizibil, atât ca valoare cât şi, uneori, ca semn. Precizia datelor şi deci și a rezultatelor este influențată de erori care provin ca urmare a unor modificări temporale, spațiale, legate de operator, de mediu etc. de la o măsurătoare la alta. Astfel, după n măsuri ale unei mărimi constante x, în condiții practic identice, se obțin n valori rezultate (x1, x2 … xn). Aceste valori, includ erori, și sunt procesate statistic fiind încadrate, de obicei, în legi de distribuție teoretice (de referință). Ca urmare, prelucrarea statistică a valorilor măsurătorilor efectuate asupra unei mărimi, urmăreşte obţinerea “celei mai bune valori” care asigură eroarea minimă între valoarea determinată şi valoarea adevărată. În fig. 2.6,a se prezintă legea distribuției normale a erorilor aleatorii, frecvent utilizată în practică. Cauzele erorilor aleatorii (imperfecţiunea organelor de simţ, deformări sau deplasări imperceptibile ale componentelor instrumentelor de măsură, variaţii ale stărilor mediului exterior etc.) sunt greu de sesizat putând fi diminuate, dar nu eliminate. Spre deosebire de erorile sistematice, care pot fi compensate prin aplicarea unei corecții (prin sumare sau multiplicare), efectele erorilor aleatorii pot fi diminuate prin creșterea numărului de măsurători. Atunci când se efectuează un număr mic de determinări experimentale a unei mărimi fizice este posibil să apară erori întâmplătoare grosoiere. Dacă într-un set de date redus (cu puţine valori măsurate), există una sau mai multe valori care diferă mult faţă de celelalte, acestea se elimină şi/sau se repetă măsurătorile. În concluzie, dacă erorile sistematice, în cazul când sunt cunoscute, pot fi corectate, cele accidentale nu pot fi evitate şi pentru diminuarea efectelor negative se măreşte numărul de măsurători. Valoarea adevărată (reală) poate fi doar aproximată, precizia aproximării fiind influenţată de erori care se impune să fie evaluate; dintre acestea unele pot fi eliminate şi altele pe cât posibil diminuate.
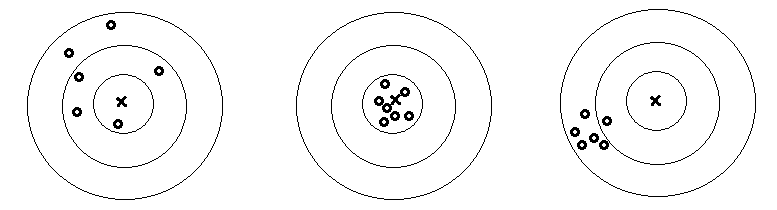
a
b c
d Fig. 2.6 Distribuția erorilor: a –
unidirecțional după curba normală (clopotul lui Gauss); b
– bidirecțională, imprecisă; c
– bidirecțională, precisă și exactă; d – bidirecțională,
inexactă Precizia de măsurare este dată de mărimea intervalului în care sunt incluse erorile. Valorile erorilor de măsurare sunt grupate în jurul unei valori medii, care sintetizează valorile măsurate. Cu cât dimensiunea acestui interval este mai mică, cu atât precizia măsurării este mai mare. Pentru asigurarea (verificarea) corectitudinii (preciziei) unui studiu ştiinţific experimental, prin evitarea obţinerii de rezultate false (sau cu abateri grosolane), se impune evaluarea (prezicerea) erorilor de măsurare. În cazul în care se impune măsurarea unei mărimi fizice, considerată cvasireală, a cărei valoare este cunoscută din literatura de specialitate, se foloseşte și noţiunea de acurateţe (exactitatea) de măsurare care indică abaterea (apropierea) centrului câmpului distribuţiei erorilor valorilor măsurate de valoarea cunoscută. Cu cât această abatere este mai redusă cu atât acurateţea rezultatelor este mai mare (acestea fiind precise și exacte) și dacă abaterea este mărită rezultatele sunt inexacte. Astfel, în practică, se pot întâlni următoarele cazuri de măsurători: imprecise, cu câmpul de distribuție a erorilor larg (fig. 2.6,b); precise și exacte cu câmpul de distribuție a erorilor îngust și cu centrul acestuia apropiat de valoarea reală (fig. 2.6,b); inexacte cu abaterea centrului câmpului de distribuție a erorilor mare (fig. 2.6,b). Pentru valorile variabilei, x = {x1, x2 … xn}, obținute prin măsurare, se pot determina următoarele erori: absolută ca diferenţa dintre rezultatul unei măsurării xi şi valoarea cuoscută a acesteia, deseori diferită de ce reală (adevărată), a mărimii măsurate, E = xi – X și relativă ca raport dintre eroarea absolută şi valoarea cunoscută, Er = 100 E/X [%]. Deoarece, abaterea (eroarea) globală asociată unui set de date nu poate fi determinată de abaterile individuale este necesar să se apeleze la metode (tehnici) statistice care au la bază metode probabilistice. În practica măsurătorilor se impune realizarea mai multor seturi de măsurători care apoi pot fi prelucrate și comparate cu metode (tehnici) statistice care urmăresc evidenţierea gradului de acceptare a abaterilor bazat pe un criteriu probabilistic. Dacă două seturi de rezultate experimentale reproductibile se cavsisuprapun, în limita erorilor acceptabile, se consideră că cele două rezultate sunt în concordanţă. Dacă diferenţa dintre cele două rezultate experimentale este mare, faţă de valori ale erorilor impuse se consideră că există un dezacord (discrepanţă) între cele două seturi rezultate. De cele mai multe ori parametrii statistici ai cazului general (populația cu numărul de valori, n → ∞), considerat teoretic, sunt estimaţi sau chiar validați de parametrii statistici ai eşantionului (număr de valori, n, redus). 2.4 ELEMENTE DE TEORIA
PRBABILITĂȚILOR APLICATE ÎN STATISTICĂ 2.4.1 Aspecte
generale Unui set de date
asociate unor măsurători, {x2,
x1, x9, x2, x1, … xn
…}
cu n valori sintetizate în variabila aleatoare x = {x1, x2 … xi
… xn}, i se poate
asocia mulţimea frecvențelor, f = {f1, f2 … fi … fn}, respectiv, a
probabilităţilor, p = {p1,
p2 … pi, … pn} cu valori determinte bazat pe
frecvențe, pi = fi/ Valoarea mediei
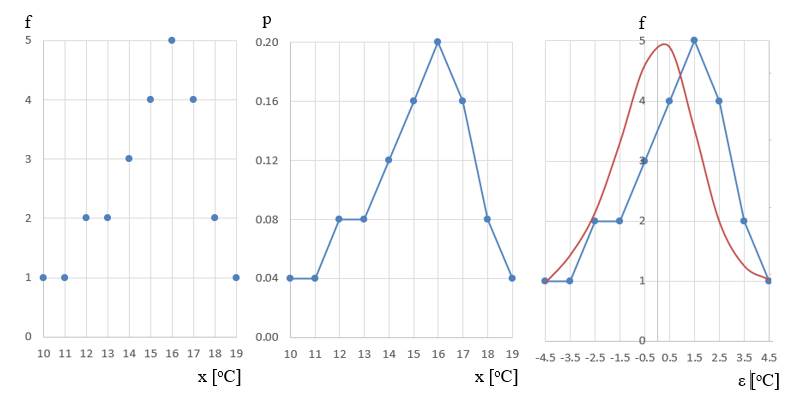
(media aritmetică) a variabilei x, m = Ex.2.1
Setului de date observate, {18, 15, 17, 15, 18, 13, 19, 15,
10, 16, 17, 11, 16, 13, 14, 15, 17, 13, 16, 17, 16, 12, 16, 14}, care
reprezintă temperaturile indicate de un termometru într-o perioadă de
timp, cu variabila aleatorie
(temperaturile observate), x =
{10, 11, 12, 13, 14, 15, 16, 17, 18, 19}, i se asociază mulțimea frecvențelor de
apariție a valorilor variabilei, f = {1, 1, 2, 2, 3, 4, 5, 4, 2, 1},
respectiv, mulțimea probabilităților, p = {1/25, 1/25, 2/25, 2/25, 3/25, 4/25, 5/25, 4/25, 2/25, 1/25}=
{0,04, 0,04, 0,08, 0,08, 0,08, 0,16, 0,2,
0,16, 0,08, 0,04} ;
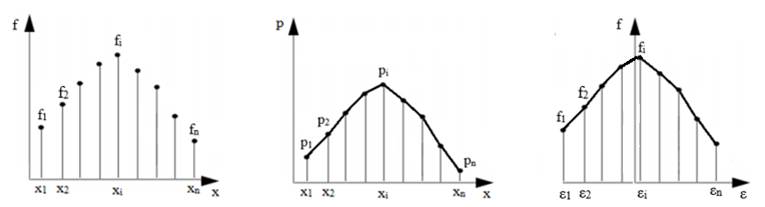
a
b c
d
e
f Fig. 2.7 Grafice
ale frecvențelor variabilelor, probabilităților variabilelor
și frecvențelor erorilor: a, b, c –
teoretice; d, e, f – personalizate Pentru realizarea de studii
probabilistice/statistice curba frecvenţelor erorilor (εi =
xi – m)
variabilelor aleatorii în raport cu media (linia frântă albastră din fig
2.7,f) se asociază (compară) cu o curbă (funcție, lege) de
referință (teoretică), marcată cu roșu. Astfel, deoarece
distribuția valorilor măsurate pe un eșantion nu se cunoaște,
aceasta se va putea asocia (compara) cu distribuții probabilistice
predefinite (de referință). De obicei, în studiile practice
se folosește curba de distribuție de
referință, asimilată cu cloptul lui Gauss (fig.2.8). În cazul numărului măsurătorilor foarte mare
(n → ∞), erorile cu valorile mari (fig. 2.8,b) au o probabilitate
mică de apariţie faţă de erorile mici care sunt mult mai probabile. 2.4.2 Distribuții
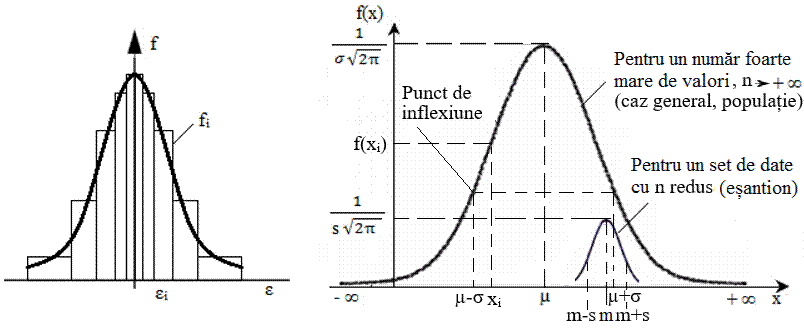
(repartiții, legi) probabilistice teoretice 2.4.2.1 Distribuția normală (Gauss) În cazul general, distribuția Gauss a unei
variabile aleatoare continue, are la bază funcţia (legea) de distribuție normală (Normal Distribution), f(x)
= în care,
μ reprezintă media, σ
– abaterea standard a variabilei aleatoare x ϵ (- ∞,
+ ∞). Această
funcție (fig. 2.8,b), numită
și distribuție gaussiană, este caracteristică volumelor mari de
valori (măsurători), n → ∞, care în practica studiilor
experimentele nu pot fi determinate ca valori numerice, fiind considerată
doar ca funcție (lege) tendinţă (ţintă, referinţă, caz general,
populație). De obicei, datele obținute prin măsurători (inclusiv, din inginerie), din considerente practice, sunt asociate unei variabile aleatoare cu număr (n) de valori redus, de obicei, asociat unui eșantion. În acest caz (fig. 2.8,b), funcția de repartiție normală, devine, f(x)
= unde, m reprezintă media, s - abaterea standard, asociate unui eșantion cu variabila aleatoare x cu n valori.
a b Fig. 2.8 Distribuția
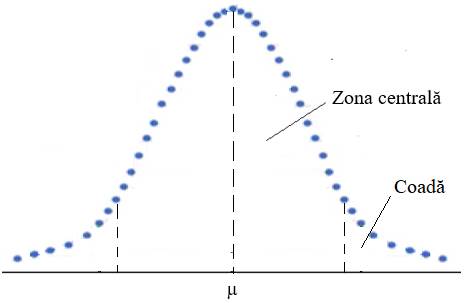
normală: a – asociată frecvenței erorilor; b – asociată funcției
distribuție normală (Gauss) Proprietăți ale distribuției normale (Gauss): - este simetrică în jurul mediei aritmetice (µ sau m) și porțiunile extreme (numite și cozi) tind la infinit (pentru cazul general, n → ∞); de fiecare parte a mediei se află jumătate din valorile distribuției; -
valoarea f(xi) reprezintă ordonata
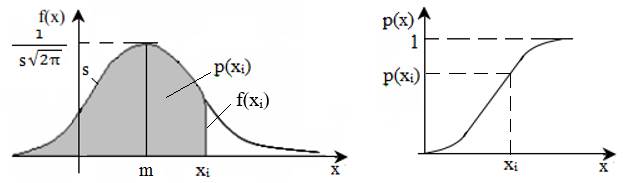
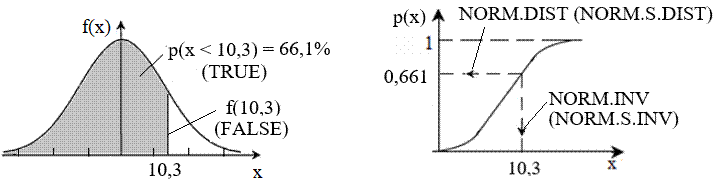
corespunzătoare valorii xi cu maximul, f(µ) = - aria totală de sub curbă, reprezintă funcția de repartiție sau densitate de probabilitate (cumulată) (Cumulative Distribution Function, CDF) corespunzătore valorii xi, se determină, pentru populație, cu relaţia (fig. 2.9,b), p(xi)
= p(x < xi) = sau,
pentru eșantion, p(xi)
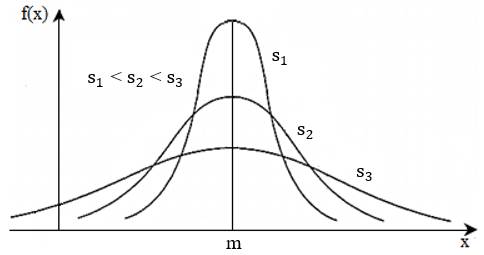
= p(x < xi) = cu valorile probabilităților, p(xi) ϵ [0,1]; valoarea maximă este este egală cu 1 arată că toate rezultatele (100%) sunt afectate de erori; - pentru valori ale abaterii standard, s, mici graficul este mai puțin împrăştiat (fig. 2.10).
a
b Fig. 2.9 :
Funcția de repartiție (densitatea de probabilitate): a –
asociată cu aria de sub curba de distribuție; b – asociată probablilității
Fig. 2.10 Forme ale curbelor de distribuție normală Pentru determinarea
valorilor funcțiilor f(xi) și p(xi) se pot
utiliza tabele sintetice cu valori predefinite sau funcția Excel
NORM.DIST (v.subcap.2.5.3.6).
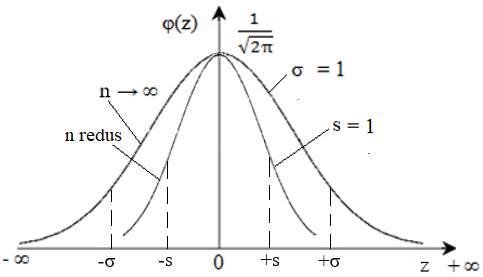
2.4.2.2 Distribuția normală standard În studiile experimentale ale fenomenelor/proceselor fizice cu măsurători, majoritatea datelor se încadrează în distribuţia normală. Dar, deoarece, deseori se impune compararea/analizarea statistică a datelor asociate aceluiași fenomen/proces fizic dar exprimate diferit (de ex. unități de măsură diferite), se poate apela la distribuţia normală standard care conduce la noi indicatori statistici facili privitor la interpretarea rezultatelor. Prin schimbarea
variabilei x în variabila adimensională, z = φ(z) = Astfel, în urma transformării se obțin: μ
= 0, σ = 1, pentru cazul general (populație),
n →∞, și m = 0, s = 1,
pentru eșantion, n finit. Valorile scorului z se pot determina din
tabele sintetice cu valori predefinite sau prin calcul numeric, de ex.
folosind funcția statistică Excel STANDARDIZE (v.subcap.2.5.3.6). Proprietăți ale distribuției normale standard: - păstrează forma distribuției inițiale (deoarece, transformarea este liniară); - prin standardizare valorile variabilei aleatorii devin adimensionale și deci, se pot face comparații statistice ale datelor asociate diverselor eșantioane; - z = 0, induce valoare nulă a mediei (m sau μ); z < 0, valoarea este mai mică ca media; z > 0, valoarea este mai mare ca media.
Fig. 2.11 Distribuții
normale standard pentru populație
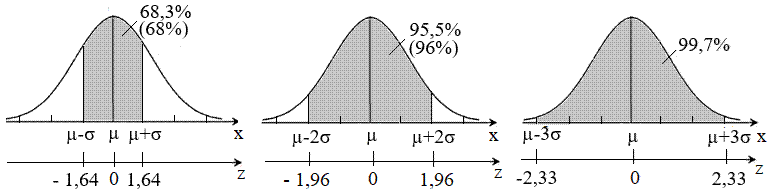
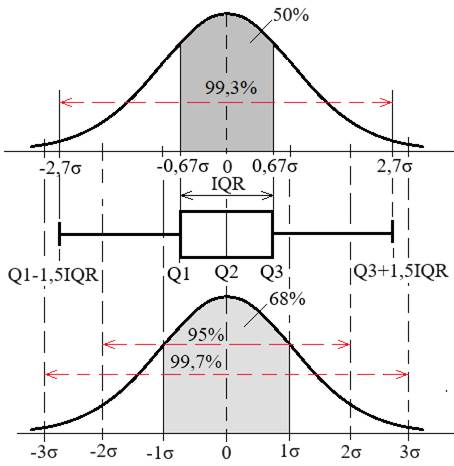
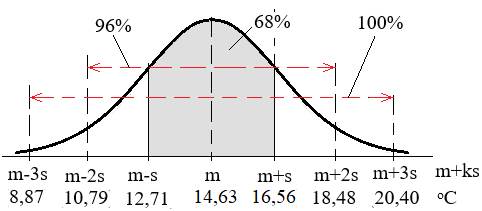
și eșantion Valoarile funcţiei densitate de probabilitate asociată distribuției normală standard pentru populație (n → ∞) precum și pentru eșantion (n finit redus) se pot obține din tabele sintetice cu valori predefinite sau prin calcul numeric, de ex. folosind funcțiile statistice Excel NORM.DIST și, respectiv, NORM.S.DIST (v.subcap.2.5.3.6). Astfel, se pot determina uşor aprecieri probabilistice privind: procentul (probabilitatea) valorilor unui set de date care se află sub o anumită valoare standard z sau procentul valorilor setului care se află într-un interval z. Cunoașterea valorilor parametrilor μ și σ (uneori, chiar teoretic), pentru cazul unei populații (n → ∞) permite, pe de-o parte, determinarea probabilității pe care o are variabilă de a se găsi într-un interval oarecare sau, pe de altă parte, determinatrea intervalului în care se poate găsi o variabilă cu o probabilitate impusă numită nivel (prag) de încredere (p), egală cu aria de sub funcţia de distribuție normală, α = 1- p, de obicei, numit nivel (prag) de semnificaţie (de risc). Astfel, s-au definit intervale de încredere, [µ - kσ, µ + kσ], centrate în raport cu media µ, pentru care nivelul de încredere are probabilitatea pk și nivelul de semnificație (risc), αk = 1 - pk. În practica studiilor statistice se folosesc, cu precădere, trei variante (valori) ale factorului k = 1, 2, 3 cărora corespund intervalele de încredere [µ - σ, µ + σ], [µ - 2σ, µ + 2σ] sau [µ - 3σ, µ + 3σ], cu nivelurile de încredere p1 = 0,683 (68,3%), p2 = 0,955 (95,5%) sau, respectiv, p3 = 0,997 (99,7%) și nivelurile de semnificație (de risc) 0,317 (31,7%), 0,045 (4,5%) sau, respectiv, 0,03 (3%). Se observă că in intervalul [- µ - 3σ, µ + 3σ] se pot identifica (găsi) aproape toate valorile variabilei x.
a
b c Fig. 2.12 Intervale și niveluri (praguri) de încredere: a –
[µ - σ, µ
+ σ], 0,683 (68,3%); b – [µ - 2σ, µ + 2σ], 0,955
(95,5%) ; c – [µ - 3σ, µ + 3σ], 0,997 (99,7%) Obs. Funcțiile Gauss
(nestandard și standard) sunt folosite frecvent în inginerie deoarece în
majoritatea proceselor de măsurare, inevitabil, intervin erori, care
prelucrate prin calcule specifice pot estima (prognoza) probabilitatea
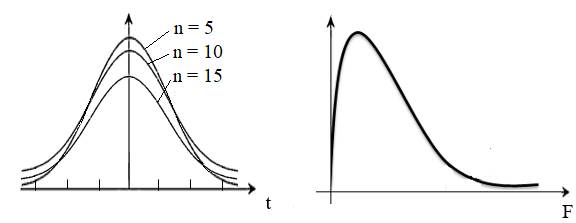
(riscul) de indentificare a unei valori date într-un domeniu impus. 2.4.2.3 Distribuția t (Student) Distribuția t se folosește pentru reprezentarea erorilor aleatoare în cazul unui număr mic de măsurători, n < 30 când distribuția Gauss nu este relevantă. Aceasta descrie o familie de distribuții dependente de mărimea eșantioanelor (fig. 2.13,a). Pentru un eșantion ce conține mai mult de 30 măsurători, distribuția t devine identică cu distribuția z .
a
b Fig. 2.13 Alte distribuții probabilistice: a –
Student; b – Fischer Valorile variabilei distribției student se dau tabelar în funcție de nivelul de încredere și numărul de măsurători (grade de libertate) sau se pot calcula cu funcții statistice. Obs. Distribuția t se poate folosi și
pentru testarea diferenței dintre eșantioane la schimbarea mediului
de măsurare. Prin schimbarea unei condiții se poate vedea dacă aceasta
are influență asupra mărimilor măsuate. Astfel, pentru două
eșantioane cu medii și abateri abateri standard diferite se pot
rezolva teste statistice t, caută să se infirme sau nu o ipoteza
preliminară (de nul) cu un anumit nivel de probabilitate impus (v.subcap.2.5.5.6.2).
2.4.2.4 Distribuția F (Fischer) Distribuția Fisher (fig. 2.13,b) definită pe intervalul [0, +∞) poate descrie comportarea raportului a două variabile aleatorii. Variabilele de tip Fisher depind de numărul măsurătorilor (gradelor de libertate) (v.subcap. 2.5.5.6.6). 2.5
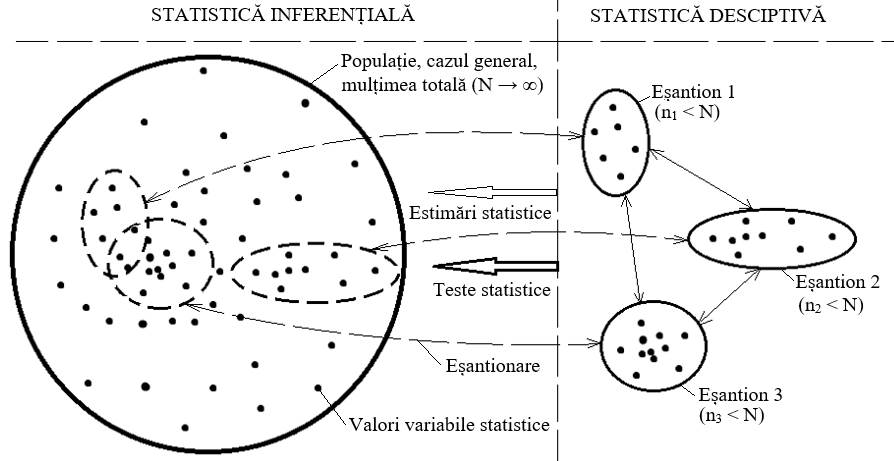
PRELUCRAREA STATISTICĂ A DATELOR EXPERIMENTALE 2.5.1 Aspecte generale Statistica este știință care se ocupă cu achiziția (culegerea), prelucrarea și interpretarea datelor, cu precădere aleatorii, bazat pe o colecţie de metode, tehnici probabilistice, asociate unor entităţi, obiecte, sisteme sau fenomene/procese în scopul descrierii comportării acestora și al determinării legilor care le guvernează. Statistica descriptivă presupune determinarea unor indicatori statistici care, pe lângă faptul că dau informaţii generale (sintetice) despre date, stau la baza analizelor statistice privind structura și organizarea datelor, cu precădere, asociate eșantioanelor (fig. 2.14). Analizele statistice descriptive, bazate pe teorii probabilistice, sintetizate în indicatori statistici caracteristici, dau cercetătorului posibilitatea de a preciza localizarea și variabilitatea (împrăştierea) datelor experimentale asociate unui fenomen/proces.
Fig. 2.14 Tipuri de studii statistice Statistica inferenţială presupune studii de bazate, de obicei, pe informaţii obținute cu statistica descriptivă (fig. 2.14), pentru a lua decizii și trage concluzii privitoare la populații, cazuri generale (teoretice) bazate pe date cu numere mari de valori. Spre deosebire de statisticile descriptive, care includ metode aplicate unui set de date, cu precădere, asociate unuia sau mai multor eșantioane (submulțimi ale cazului general, populației), statisticile inferențiale urmăresc prin metode specifice (teste statistice) deducerea și estimarea unor parametri și/sau legi asociate cazului general (populației). Analizele (testele) statistice inferențiale, de obicei, se fac în continuarea analizelor descriptive bazate pe experimente, și au ca obiectiv obținerea de valori și/sau concluzii privind aprecierea generală a comportării fenomenului/procesului. Analizele statistice descriptive și inferențiale ale datelor experimentale, în cadrul acestei lucrări, se fac cu funcții statistice ale pachetului software Microsoft Excel grupate în modulul Data Analysis care se activează de utilizator (v.Ghid.Excel.02). 2.5.2 Variabile statistice Variabila statistică este o submulțime de valori aleatoare care, de obicei în inginerie, reprezintă prin atribute (greutate, culoare, mărime, presiune etc.)caracteristici specifice ale obiectelor și/sau fenomenelor/proceselor fizice. Aceasta poate avea un număr finit de valori numerice (cantitative) sau alfanumerice (calitative) care se asociază (tab. 2.1), de obicei, unui eșantion. Valorile cantitative, frecvent, reprezintă mărimi cu unități de măsură asociate fenomenelor/proceselor fizice cercetate, de obicei, unităţi naturale ale unor mărimi fizice (masa (kg), volumul (m3), lungimea (m), forţa (N) etc. În general, variabilele statistice pot fi încadrate în două grupe: calitative și cantitative (tab. 2.1) Variabile calitative (categoriale), de obicei, alfanumerice nu se determină prin măsurare; în practică acestora li se pot asocia și numere cu care nu se vor efectua operții algebrice; cuantificarea valorilor calitative, de obicei, se face face procentual (%). Variabile cantitative sunt asociate unor caracteristici (parametri) măsurabile, de obicei, sub forma unui set de valori numerice care se pot ordona; variabile cantitative continue se transformă în variabile calitative prin împărțirea în clase (conform unor reguli convenționale) ex. intrervalului 0 … 20 se asociază valoarea ”bun”; 20 … 50, „foarte bun”; 50 … 80, excelent” etc.
Obs. Tipul variabilelor statistice se alege corelat cu tipul analizelor și testelor statistice ce se vor realiza în continuare. 2.5.3 Elemente de statistică
descriptivă 2.5.3.1 Indicatori
statistici descriptvi, generalități Pentru studii statistice a grupării valorilor și/ sau erorilor se impune definirea unor indicatori care descriu calitativ și/sau cantitativ dispersia (împrăștiera) valorilor variabilei aleatorii în jurul unei valori medii, de obicei, media aritmetică. Indicatorii statistici (tab. 2.2) se reprezintă prin valori numerice ce permit caracterizarea din punct de vedere cantitativ și/sau calitativ a unuia sau mai multe seturi de date asociate unui obiect, fenomen, proces sau sistem fizic; în plus, aceștia pot descrie și evoluţia în funcţie de condiţiile concrete de experimentare precum şi compararea seturilor de măsurători diferite.
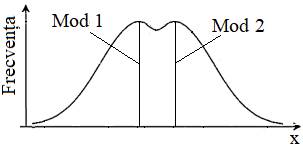
2.5.3.2 Indicatori statistici ai
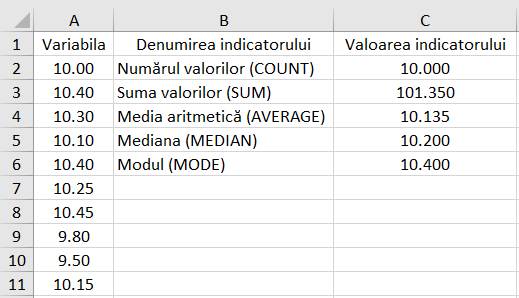
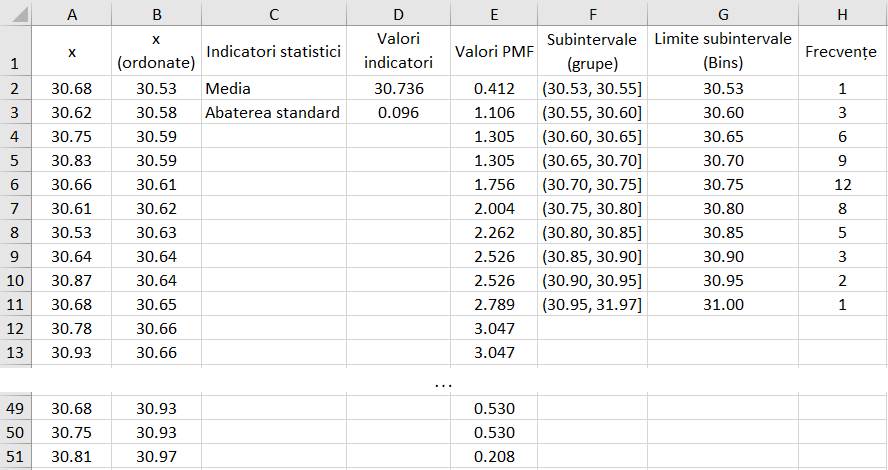
tendinței centrale (de medie): Media, Mediana, Modul Ap.2.01 Determinarea
indicatorilor tendinței centrale pentru un set de măsurători (variabila
x) cu n = 10 valori (coloana A din fig. 2.15) (Ghid.Ap.2.01)
Fig. 2.15 Tabel cu valori ale datelor și
indicatorilor Fig. 2.16 Graficul
funcției MODE
a
b
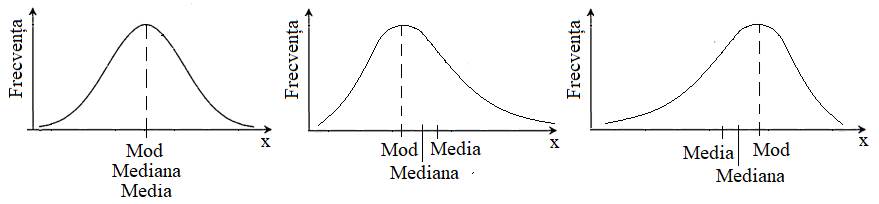
c Fig. 2.17 Variante
posibile ale indicatorilor de medie:
a – valori identice; b –
valori crescătoare în ordine Mod, Mediana, Media; b – valori crescătoare în ordine Media,
Mediana, Mod 2.5.3.3 Indicatori statistici de poziționare
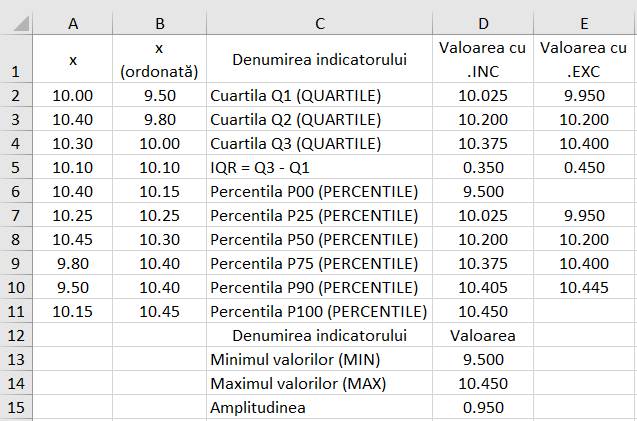
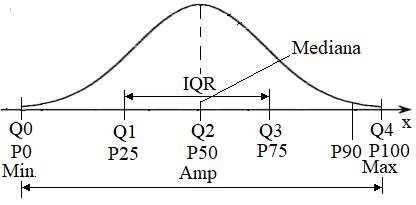
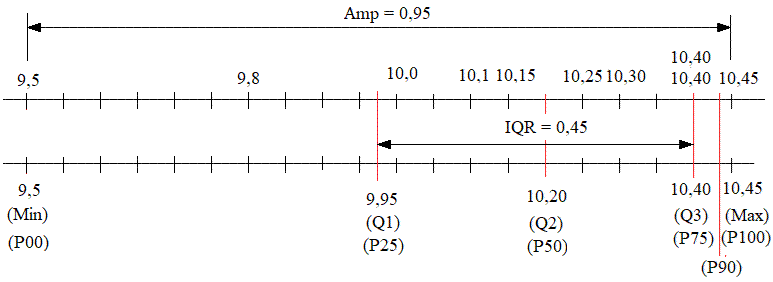
(localizare): Maximul/Minimul, Amplitudininea (Range), Caurtile, Percentile Ap.2.02 Determinarea
a indicatorilor de poziționare pentru un set de măsurători (variabila x)
cu n = 10 valori (coloana A din fig. 2.18) (Ghid.Ap.2.02)
Fig. 2.18 Tabelul cu valori ale datelor și
indicatorilor
a
b
c Fig. 2.19 Localizări ale
valorilor generate cu funcțiile Excel, QUARTILE și PERCENTILE: a –
în raport cu indicatorii de medie la general; b, c –
în raport cu indicatorii de medie personalizați 2.5.3.4 Indicatori statistici ai
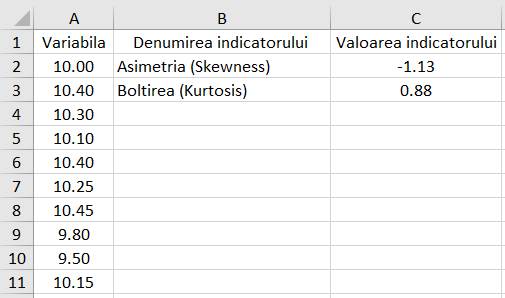
formei distribuției: Asimetria (skewness), Boltirea (kurtosis) Ap.2.03 Determinarea
indicatorilor formei distribuției pentru un set de măsurători (variabila
x) cu n = 10 valori (coloana A din
fig. 2.20) (Ghid.Ap.2.03)
Fig. 2.20 Tabel cu valori ale datelor și
indicatorilor
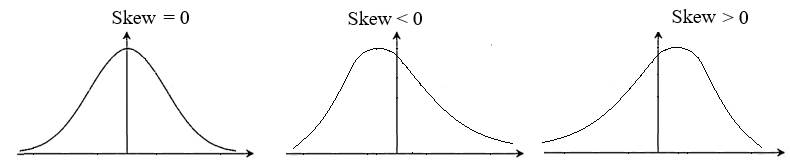
a
b
c Fig. 2.21 Forme de poziționare a distribuției datelor în
raport cu distribuția normală în
jurul mediei: a – simetrică; b – asimetrică negativ; c – asimetrică pozitiv
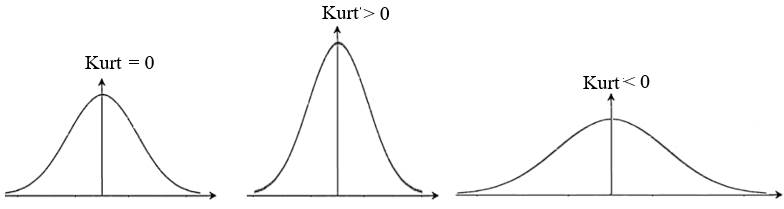
a b c Fig. 2.22 Forme privind ascuțirea
(aplatisarea) distribuției datelor în raport cu
distribuția normală în jurul
mediei: a – nedeformată; b – ascuțită; c – aplatisată 2.5.3.5 Indicatori statistici de dipsersie (împrăștiere): Dispersia
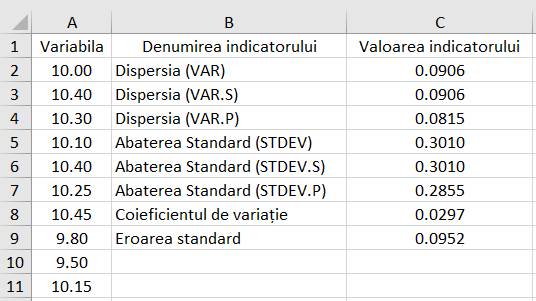
(variance), Abaterea standard (standard deviation), Coieficientul de
variație, Eroarea standard Ap.2.04 Determinarea
indicatorilor de dispersie (împrăștiere) pentru un set de măsurători
(variabila x) cu n = 10 valori (coloana A din fig. 2.23) (Ghid.Ap.2.04)
Fig. 2.23 Tabel cu valori ale datelor și
indicatorilor
a
b
c Fig. 2.24 Forme de împrăștiere (grupare)
a datelor în jurul mediei: a – apropiată de medie; b – preponderent în dreapta; c – depărtată de medie 2.5.3.6 Indicatori statistici de probabilitate: Transformata z, Densitatea de
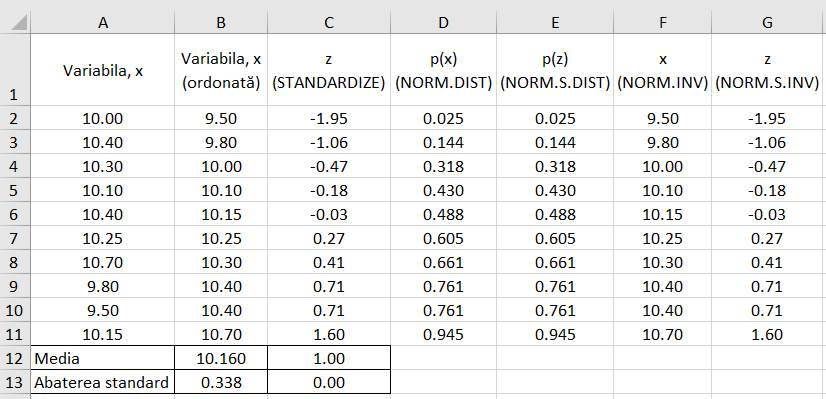
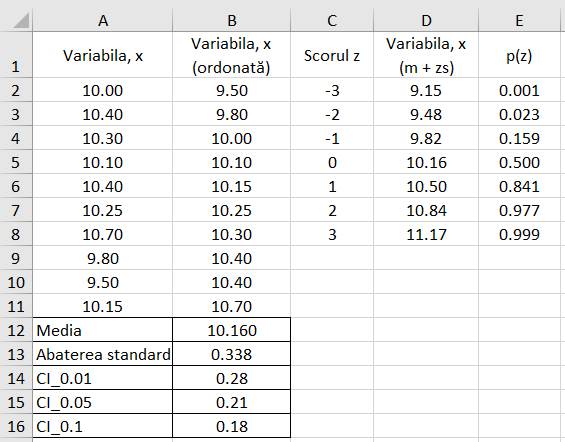
probabilitate (probabilitatea cumulată), Scorul z, Intervalul de încredere Ap.2.05 Determinarea
indicatorilor de probabilitate pentru un set de măsurători (variabila x) cu n
= 10 valori (coloana A din fig. 2.25) (Ghid.Ap.2.05)
Fig. 2.25 Tabel cu valori ale datelor și
indicatorilor
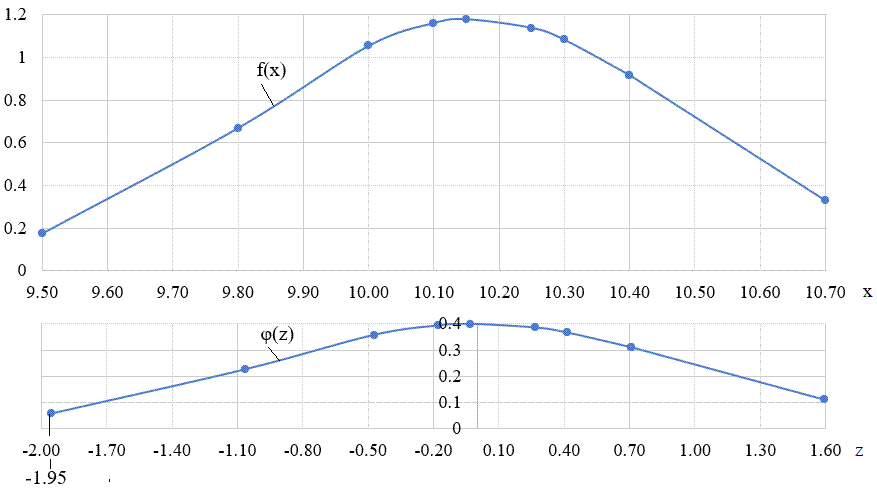
Fig. 2.26 Transformata
φ(z) a funcției f(x)
a
b Fig. 2.27 Funcții
probabilistice: a – de repartiție cu densitatea
cumulată (CDF) și punctuală
(PMF); b – cu funcțiile densitate de probabilitate
Excel, directă și inversă
Fig. 2.28 Tabel
cu valori ale datelor și ale indicatorilor de probabilitate
Fig. 2.29 Corespondența
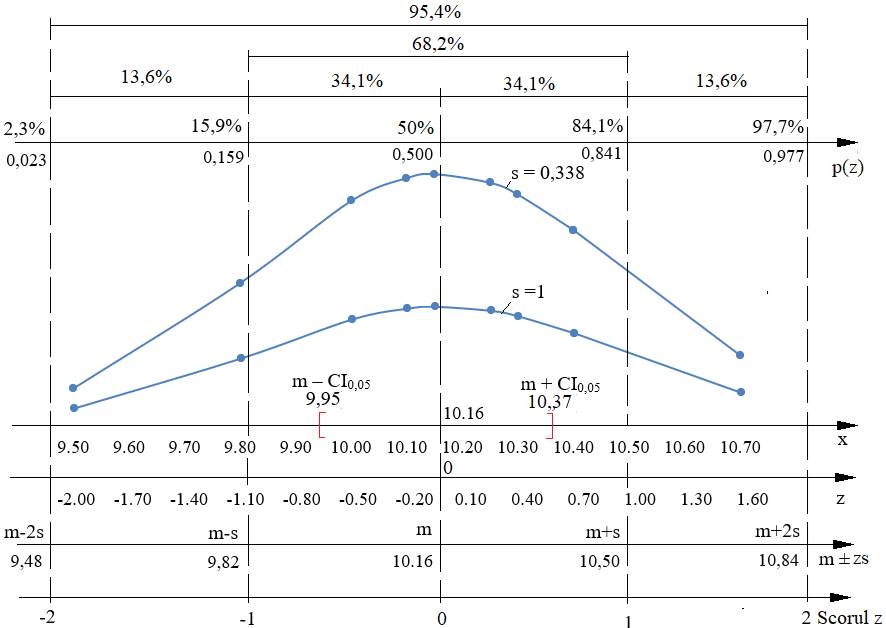
valorilor densității de probabilitate în coordonate x, z și unități de abatere standard
a b c Fig. 2.30 Intervale
de încredere și
probabilitățile corespunzătoare, asociate: a –
unei unități standard; b – a două unități standard; c – a trei unități standard 2.5.3.7 Indicatori statistici de corelare (asociere)
a două variabile: Coeficientul de covarianță, Coeficentul de
corelație, Matricea de
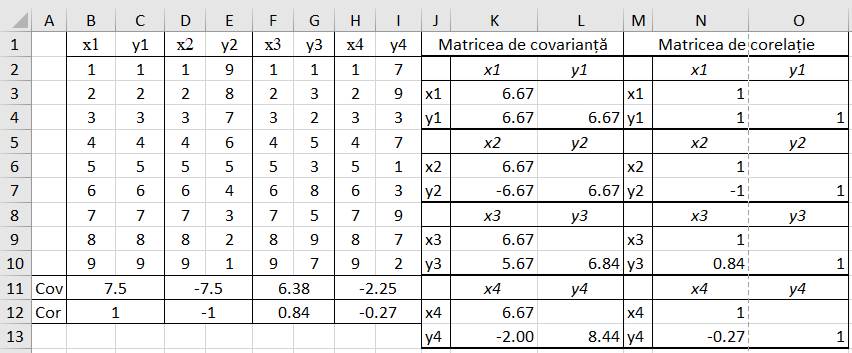
covarianță Ap.2.06 Determinarea
indicatorilor statistici de corelare (asociere) pentru un set de măsurători
(perechile (x1, y1), (x2, y2), (x3,
y3) … (x9, y9)) cu n = 9 valori din coloanele
B, C, D, E, F, G, H, I din fig. 2.31 (Ghid.Ap.2.06).
Fig. 2.31 Tabel cu valori ale datelor și
indicatorilor de corelare
2.5.4 Analize statistice descriptive În practică, nu se pot face un număr foarte mare de măsurători şi, deci, valoarea reală (adevărată) nu se poate determina direct. Generarea unei curbe de distribuție ce caracterizează populația statistică (cazul teoretic, general) din care face parte eșantionul (cu un număr de valori redus) este primul pas al statisticii descriptive bazată pe legi probabilistice. Pentru cazul teoretic (populația statistică cu un număr infinit de valori) indicatorii principali, media μ și dispersia (varianța) σ2, se vor determina prin studii (analize) statistice descriptive bazate pe indicatorii principali, m și s2, asociați valorilor obținute prin măsurare la nivel de eșantion. Analizele
statistice se ocupă cu
descrierea, organizarea și sistematizarea trăsăturilor unui set de date
obținut prin măsurare, de obicei, asociat unui eșantion, care se
pot face prin analiza valorilor unor indicatori statistici (media,
dispersia, mediana, cuantile, tendințe etc.) sintetizați tabelar
cât şi/sau prin grafice (prin puncte, cu linii, histograme, boxplot etc.). 2.5.4.1 Analize
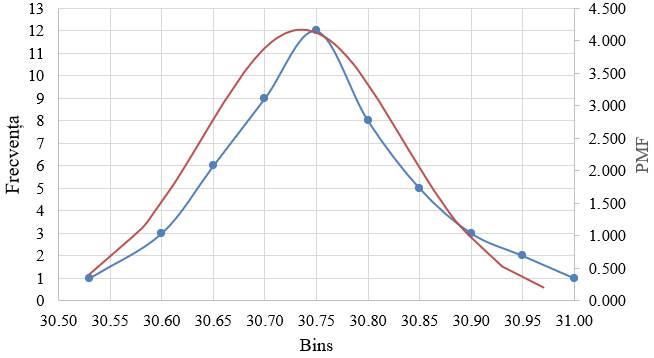
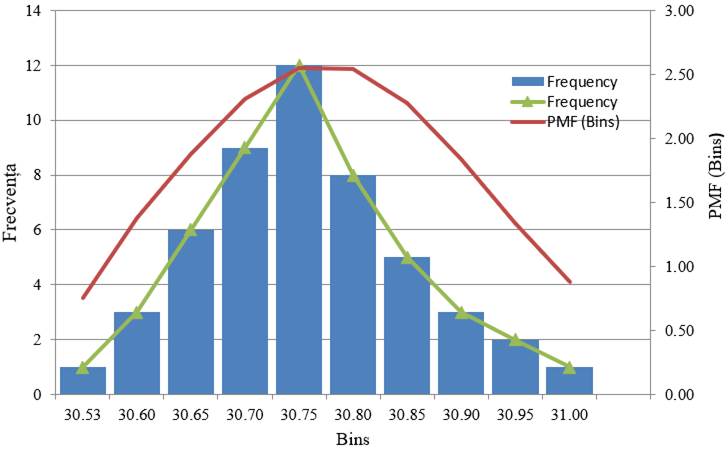
statistice descriptive bazate pe reprezentări grafice ale frecvențelor Ap.2.07 Determinarea
pornind de la valorile un set de măsurători (coloana A din fig. 2.33) a
grupelor (subintervalelor, claselor) de valori ale frecvențelor,
poligonului frecvențelor, histogramei frecvențelor, graficului distribuției
normale etc. (Ghid.Ap.2.07)
Fig.
2.33 Tabel cu valori ale datelor,
indicatorilor și frecvențelor
Fig.
2.34 Curba
distribuției normală asociată curbei frecvențelor
Fig.
2.35 Curba
distribuției normală asociată histogramei și poligonului
frecvențelor
Fig.
2.36 Curba teoretică ideală (Gauss) a distribuției normală (pentru
un număr foarte mare de valori, n → ∞) 2.5.4.2 Analize
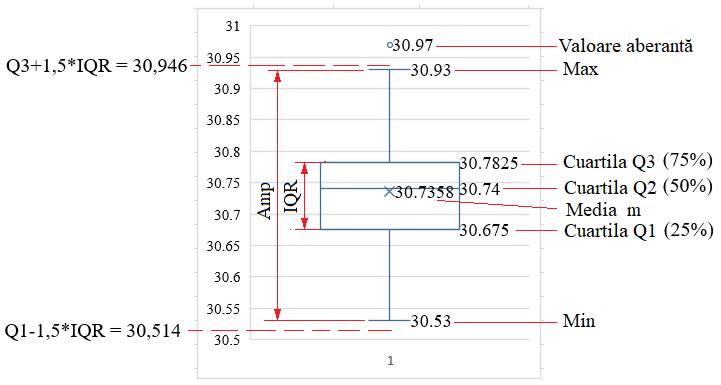
statistice descriptive bazate pe reprezentări grafice de tip boxplot Ap.2.08 Studiul,
pornind de la valorile un set de măsurători (coloana A, din fig. 2.33), a unor
aspecte privind: grafice boxplot și cazuri posibile; evidențierea
valorilor aberante folosind regulile IQR și Standard Deviation
(68-95-99,7) (Ghid.Ap.2.08)
Fig. 2.37 Structura
generală a graficului boxplot asociată datelor din fig. 2.33
a
b
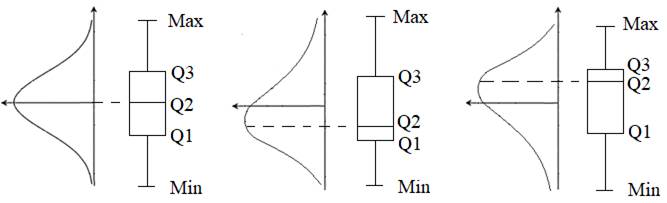
c Fig. 2.38 Forme
ale graficelor boxplot asociate cu forme ale disttribuției normale în jurul mediei: a – simetrică; b –
asimetrică negativ; c –
asimetrică pozitiv
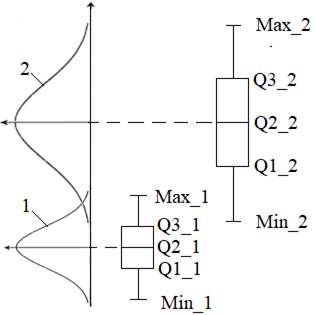
Fig.2.39
Grafice boxplot
asociate cu două distribuții normale
Fig.2.40 Graficul boxplot corelat cu distribuția normală dependentă de
valori ale abaterilor standard 2.5.4.3 Analize
statistice descriptive bazate pe reprezentări grafice a distribuției
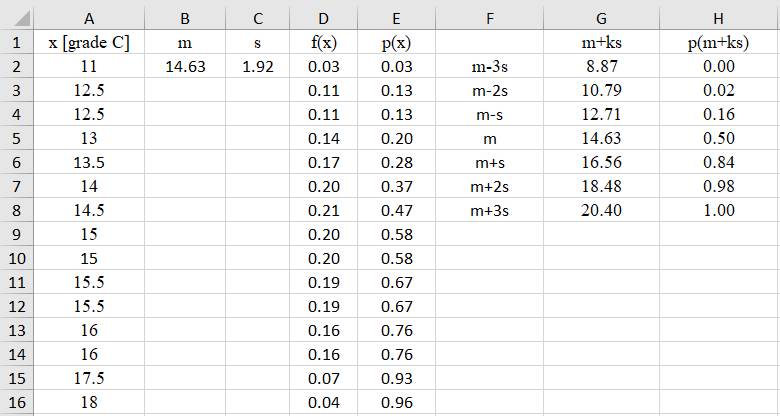
(repartiției) datelor Ap.2.09 Studiul
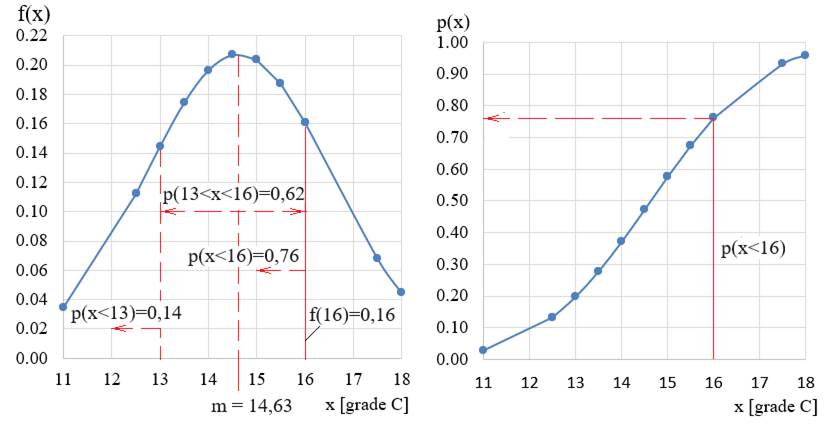
statistic bazat pe funcțiile de distribuție (repartiție)
și probabilitate a unui set de date asociat temperaturilor unui corp
(coloanal A, fig. 2.41) în vederea stabilirii temperaturii medii (Ghid.Ap.09).
Fig.2.41 Tabel cu valori ale datelor,
indicatorilor și probabilităților
Fig.2.42
Valori ale
probabilităților cumulate corespunzătoare unor valori distincte sau
intervale
2.5.4.4 Analize
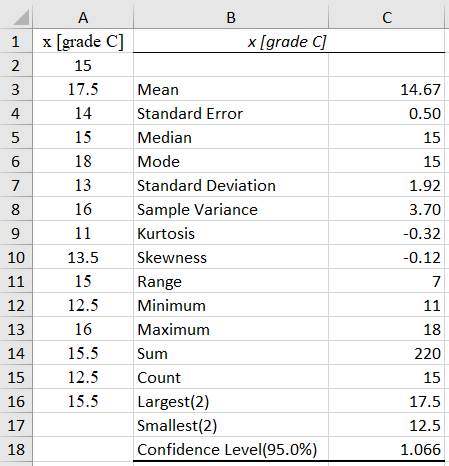
statistice descriptive bazate pe valori ale indicatorilor statistici Ap.2.10 Studiul statistic, bazat pe valori ale indicatorilor obținuți cu funcția Descripive statistics din modulul Data Analysis, a unui set de date asociat temperaturilor unui corp (coloana A, fig.2.44) în vederea stabilirii temperaturii medii (Ghid.Ap.2.10).
Fig. 2.44 Tabel cu
valori ale datelor și indicatorilor |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||