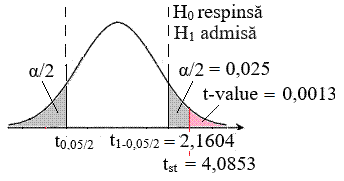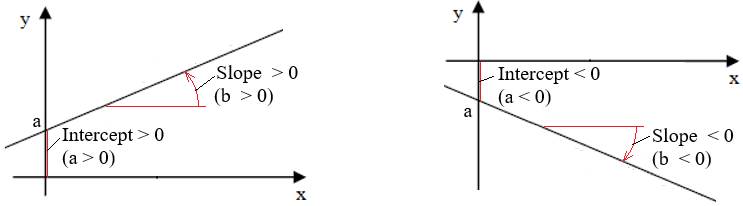|
Mogan
Gh.L., Butnariu S.L., Buzdugan I.D.
Organe de mașini. Lucrări de laborator. Universitatea Transilvania din Brașov
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
1. PRELUCRAREA ŞI ANALIZA STATISTICĂ A
DATELOR EXPERIMENTALE |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2.5.5
Analize
statistice inferenţiale (deductive) 2.5.5.1
Aspecte generale În multe probleme de inginerie se pune problema acceptării sau respingerii valorilor obținute prin măsurători. Atunci cînd o investigaţie de tip statistic se efectuează bazat pe date asociate unui eşantion, orice rezultat obţinut are o valoare relativă, în sensul că datele respective nu numai că nu coincid cu cele referitoare la cazul general (populaţia statistică), dar nici măcar nu se poate afirma cu certitudine care este diferenţa dintre cele două seturi de date, asociate eșantionului și populației, care, de regulă, sunt necunoscute. Statistica inferenţială (inductivă, deductivă) permite obţinerea
de concluzii cvasiprecise (uneori,
precise) despre anumite trăsături (caracteristici) ale unei mulţimi
(populație, caz general, caz teoretic), de obicei, cu un număr foarte
mare de valori (teoretic infinit). Analizele inferențiale de obicei au
la bază o submulţime (uneori, două sau mai multe) asociată unui eșantion
cu un număr finit, de regulă mult redus, de valori (frecvent, n <
30). Spre deosebire de staistica
descriptivă, care trage concluzii bazat pe date (indicatori) cu valori ferme,
prin statistica inferențială se ajunge la date (concluzii) noi bazat pe legi
probabilistice aplicate la nivel de eșantion (eșantioane). Concluziile (deciziile, estimările, extrapolările) ca rezultat al studiilor inferențiale sunt validate, de obicei sub rezerva unor certititudini/incertitudini (probabilități impuse/riscuri acceptate) pentru o mulţime infinită (cazul general, populație statistică), bazat pe indicatori statistici descriptivi asociați datelor unuia sau mai multor submulțimi (eșantioane) cu numere de valori, obținute prin măsurare, reduse. Scopul inferenţelor (testelor) statistice este să
determine dacă există suficiente dovezi statistice care să permită să se concluzioneze
că o afirmaţie (ipoteză) despre un parametru este adevărată. Testele statistice verifică dacă una sau mai multe ipoteze
formulate cu privire la o populație au șanse să fie adevărate; de ex.
dacă pentru valorile unui experiment se observă concordanțe/diferențe
de comportare a valorilor la nivel de eșantion, oare și la nivel de
populație (caz general) apar concordanțe/diferențe; în urma
testului statistic se poate răspunde: da/nu, acceptat/respins. Metodele și tehnicile statisticii inferențiale, spre deosebire ale statisticii descriptive (de obicei, comparative), pot fi: de predicție (estimare) a unor caracteristici comune ale populației și de decizie, care implică verificarea unor ipoteze statistice la nivel de populații formulate pe baza rezultatelor obținute la nivel de eșantion. Astfel, testele statistice răspunde la întrebări (ipoteze) care se referă la comportarea (evoluția) fenomenelelor sau proceselor studiate. Statistica deductivă are ca scop obținerea de decizii (concluzii) despre datele de analizat care pot lua diverse forme: răspunsuri da/nu la întrebări despre ipoteze asociate datelor (teste de decizie), estimarea caracteristicilor numerice ale datelor (teste de estimare), descrierea asocierii și/sau corelațiilor de date (teste de corelare). 2.5.5.2 Modelarea problemelor de statistică inferențială În studiile experimentale
(inclusiv, cele inginerești) verificarea ipotezelor ştiinţifice se face cu teste specifice bazate pe ipoteze statistice, formulate la nivel de populație (cazul general, N → ∞) pentru a
arăta care sunt certitudinile ca acestea să fie adevărate. Astfel, se
testează ipoteze asociate cazului general, formulate pe baza datelor
obținute pentru unul sau mai multe eșantioane (cu, numărul de
măsurători, n, mic). Ipoteza statistică (parametrică) este o afirmație
(presupunere) cu privire la parametri (indicatori) statistici (de obicei, media
și/sau dispersia) asociați unei variabile corespunzătoare
unei populații care se verifică, având la bază un set de date de
măsurare (asociate unui eșantion), cu ajutorul unui test statistic;
în urma rezolvării acestuia ipoteza statistică se poate accepta sau
respinge cu o probabilitate (risc) impusă. Testele
statistice sunt metode prin care se iau
decizii, care permit, ca pentru unul sau mai multe seturi de date
experimentale, valori numerice, să se valideze anumite estimări de parametri
asociați unei repartiţii probabilistice sau chiar, uneori, să se poată prezice
forma legii de repartiţie a datelor. Prin aceste metode se verifică o ipoteză
de nul (de obicei, cea pe
care cercetătorul urmărește să fie invalidată) care dacă va fi respinsă
se va accepta, ipoteza alternativă și, deci, se confirmă
ipoteza de cercetare. Ipoteza de nul presupune (intuieşte) apriori ca fiind
adevărată situaţia cea mai apropiată de realitate, desigur cu admiterea
caracterului întâmplător al abaterilor. Aceasta se specifică cu simbolul “=” (egalitate statistică, care ca valoare numerică poate fi
diferită), adică, nu există nicio
diferență, cu o probabilitae impusă, între parametrii studiați
(medie, disperse). Ipoteza alternativă
reprezintă o situație admisibilă contrară (opusă) cu ipoteza nulă
(există diferență între parametri studiați, de obicei, conform
ipotezei de cercetare). Aceasta se specifică cu simbolurile: “>”, “<” sau “≠”. Prin respingerea ipotezei de nul (la un nivel de semnificație (risc) statistică) se indică că rezultatele observate (diferențele) nu sunt datorită întâmplărilor și SUNT semnificative statistic. Când ipoteza de nul este acceptată se indică că diferenţele observate sunt din cauza întâmplărilor şi rezultatele NU SUNT semnificative statistic. La testarea ipotezelor statistice sunt posibile deciziile din tab.2.2; ipoteza
nulă se respinge sau se acceptă (sau nu sunt motive de respingere a ei).
Deci, testele statistice sunt metode (tehnici) de decizie care stau la
baza validării sau invalidării cu un anumit grad de certitudine (risc) a unei
ipoteze statistice. Semnificația
statistică a unui test este indicată de probabilitatea de a obține o
eroare de tip I. În cazul deciziilor false se pune problema minimizării
erorilor posibile (de tip I și de tip
II), de obicei, se minimizează eroarea cea mai dezavantajoasă (dependent de
aplicație). Tab. 2.2 Tipuri
de decizii dependente de starea ipotezei de nul
Nivelul de semnificație (risc), de obicei, notat α, indică, pe de-o parte, probabilitatea maximă cu care se respinge ipoteza de nul (când, de fapt aceasta este adevărată) sau pe de altă parte, mărimea riscului (erorii) pe care cercetătorul este dispus să îl accepte; valori uzuale: α = 0,01 (1%), nivel puternic semnificativ, α = 0,05 (5%), nivel normal semnificativ sau α = 0,1 (10%), nivel slab semnificativ. Nivelul de încredere, de obicei notat, p = 1- α, reprezintă proabilitatea ca valorile rezultate să fie garantate (certe); corespunzător valorilor uzuale ale lui α: p = 0,99 (99%), p = 0,95 (95%), respectiv, p = 0,90 (90%). 2.5.5.3
Alegerea tipului
testului statistic Alegerea
testului adecvat se face, pe de o parte, în funcţie de datele obținute
prin măsurare (tipurile variabilelor), iar pe de altă parte, în funcţie de
scopul urmărit. În cazul variabilelor numerice (rezultatele unor măsurători),
se pot alege între două grupe de teste: parametrice şi nonparametrice. Testele parametrice
au la bază presupunerea că datele provin dintr-o populaţie cu distribuţie
normală (Gauss), iar testele cel mai des folosite sunt: testul z, testul t
(Student), testul Fisher, de analiza a varianţei ANOVA (ANalysis Of VAriance).
Testele
nonparametrice nu
implică cunoașterea distribuției valorilor se bazează pe analiza
ordinei valorilor, de obicei, neluând în considerare valori exacte operând cu
valori arbitrare, cu grade de ambiguitate necontrolate; aceste teste, de
obicei, fiind neadecvate pentru studiile experimentale inginerești nu se
vor trata în continuare. Teste statistice parametrice pentru verificarea ipotezelor
statistice asupra parametrilor repartiției normale (media și/sau
dispersia), frecvent, se folosesc pentru eșantioane cu: -
n
≥ 30…100, cu repartiția normală; în practică se pot întâlni
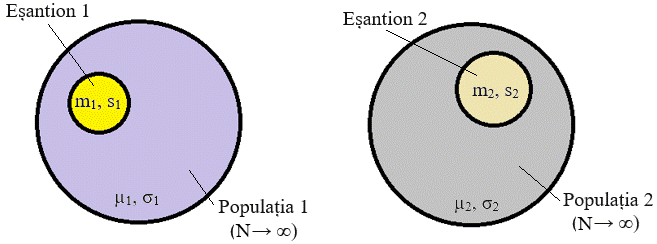
următoarele variante: - testul z pentru medie (o variabilă), când NU se cunoaște dispersia populației σ2; - testul t pentru medie (o variabilă), când se cunoaște dispersia populației σ2 (este robust și mai stabil, deoarece are la bază dispersia populației); - testul z pentru medii (două variabile, fig. 2.46),
când NU se cunosc dispersiile populației - testul t pentru medii (două variabile, fig. 2.46),
când NU se cunosc dispersiile populației și sunt diferite - testul t pentru medii (două variabile, fig. 2.46),
când NU se cunosc dispersiile populației dar se consideră egale ( - testul F pentru dispersii (două variabile, fig. 2.46). -
n < 30 (eșantioane mici), chiar dacă variabila este normală, NU
se folosesc testele z (deoarece rezultatele sunt alterate din cauza volumului
de selecție, n, mic), se folosesc teste t indiferent dacă se
cunoaște sau nu dispersia variabilei.
Fig.
2.46 Parametri
principali a două populații
și eșantioane asociate Obs. - spre deosebire de testul z care folosește și parametri de populație, fiind mai robust, testul t, bazat pe parametri de eșantion, este mai slab; - pentru cazurile cu mai mult de două variabile se poate folosi testul ANOVA. -
în general, datele statistice legate de medie sunt înfluențate de
dispersie și deci, fiind dependente de abaterea standard (σ), pun
în evidență pe lângă tendința centrală (media) și variabilitatea. 2.5.5.4
Descrierea
(formularea) problemei statistice Pentru aplicarea unei
analize (test) statistice deductivă de decizie, preliminar, se stabilesc
următoarele: -
definirea
populației statistice cu parametri µ, σ (de obicei, cu valori necunoscute);
- nivelul de semnificație (risc), α; nivelul de încredere, p = 1- α; -
volumul
eșantionului (eșantioanelor): n valori; -
caractersistica
(proprietatea) de interes, variabila
aleatoare asociată, {x1, x2, …. xn}, cu indicatorii statistici principali
(m, s) cunoscuți; -
θ0,
parametrul de interes, impus (de obicei,
o valoare de medie sau de dispersie); -
funcția
statistică (normală (standard),
Student t, Fischet F etc.)
cu repartițe cunoscută; -
alegerea
tipului testului statistic potrivit parametrului de interes și datelor
aplicației. 2.5.5.5
Algoritm
general de rezolvare a testelor statistice de semnificație a. Formularea ipotezelor Ipotezele statistice se stabilesc conform tab. 2.3. Tab. 2.3 Formularea
ipotezelor testelor de decizie
Obs. Ipoteza alternativă decide denumirea
testului (unilateral stânga/dreapta sau bilateral). În practică sunt preferate
ipotezele asociate cu testele unilaterale, deoarece conduc la rezultate mai
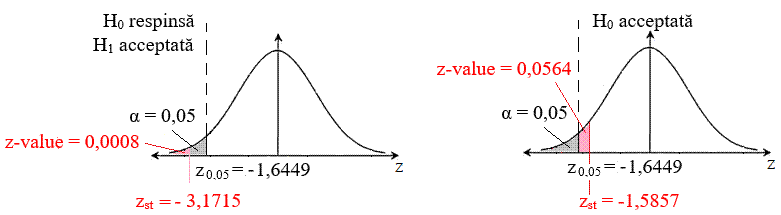
relevante. b. Adoptarea funcției statistice (FS), determinarea valorii acesteia și a semnificației statistice Funcția statistică poate fi: normală (standard), Student t, Fischet F etc.; valoarea statistică ust rezultă din ecuația FS(u) = θ0; semnificația statistică efectivă, u-value = FS(zst); valorile și semnificațiile statistice se pot determina cu funcții Excel. c. Determinarea valorii critice Se determină cα, c1-α sau cα/2, c1-α/2 din ecuația FS(c) = α; valorile se pot obține și cu funcții Excel; valoarea critică reprezintă cuantila de ordinul α egală cu aria de sub curba de reparție (probabilitatea) pentru valoarea x < c. Valoarea nivelului (pragului) de semnificație, α (0,01, 0,05 (frecvent folosit) sau 0,1), se stabilește în funcție de tipul aplicației. Obs. valoarea critică împarte mulțimea valorilor statistice în două regiuni (fig. 2.47): critică (de respingere a ipotezei H0, respectiv de acceptare a ipotezei alternative H1), necritică (de acceptare a ipotezei H0). d. Concluzia (decizia) privind acceptarea/respingerea ipotezei de nul Prin compararea valorii statistice ust cu valori critice cα sau a valorii pragului de semnificație u-value cu α, se pot obține variantele: Cazul
testului unilateral stânga
(left one-tail, fig. 2.47,a) ust > cα (u-value > α), ipoteza de nul H0 este acceptată și este nesemnificativă statistic (probabilitatea p = α); ust < cα (u-value < α), ipoteza de nul H0 este respinsă și este semnificativă statistic; se acceptă H1, ipoteza cercetării se confirmă) cu probabilitatea p = 1-α. Cazul testului
unilateral dreapta (right
one-tail, fig. 2.47,b) ust < cα (u-value > α), ipoteza de nul H0 este acceptată și este nesemnificativă statistic (probabilitatea p = α); ust > cα (u-value < α), ipoteza de nul H0 este respinsă și este semnificativă statistic; se acceptă H1, ipoteza cercetării se confirmă cu probabilitatea p = 1-α. Cazul testului
bilateral (two-tail (două cozi), fig.2.47,c) ust > cα/2 sau ust < c1-α/2 (u-value > α/2), ipoteza de nul H0 este acceptată și este nesemnificativă statistic (probabilitatea p = α); ust < cα/2 sau u > c1-α/2 (u-value < α/2), ipoteza de nul H0 este respinsă și este semnificativă statistic; se acceptă H1, ipoteza cercetării se confirmă cu probabilitatea p = 1-α.
a b
c Fig. 2.47 Cazuri posibile ale testelor de decizie:
a - unilateral stânga (left one-tail, coadă stânga); b -unilateral
dreapta (right one-tail, coadă
dreapta); c - bilateral
(two tail, două cozi) 2.5.5.6
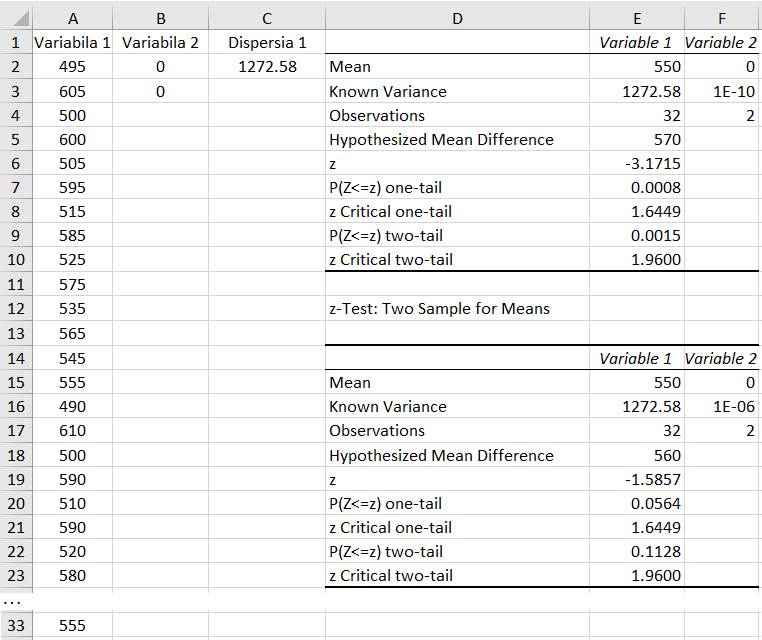
Analize (teste) statistice de decizie/estimare 2.5.5.6.1 Aplicație testul z
de medie pentru o variabilă Ap.2.11 Să se verifice condiția de rezistența (să NU cedeze) la rupere a materialului unui lot de peste 10000 de piese, R < R0 = 570 MPa cu probabilitatea 95% (ipoteza de cercetare), pornind de la un set de măsurători cu n =32 valori, ale tensiunilor efective (coloana A, fig. 2.48). Se consideră că distribuția valorilor variabilei, tensiunile efective, este normală (Ghid.Ap.2.11). Descrierea problemei statistice: -
definirea
populației: valorile rezistențelor
(tensiunilor) efective ale pieselor lotului; se cunosc parametrii µ, σ
considerați ca fiind egali cu ai eșantionului (acesta având volum
mare, n ≥ 30; - nivelul de semnificație: α = 0,05 (5%); nivelul de încredere (certitudine), p = 1- α = 0,95 (95%); -
volumul
eșantionului: n = 32, valori (coloana
A, fig. 2.47); -
caractersistica
(proprietatea) de interes, variabila aleatoare: valorile (rezistențelor)
tensiunilor efective, R, au distribuție normală (m, s); -
parametrul
de interes; media m cu valoarea de referință R0 = 570 MPa; -
funcția
statistică: normală, f(x), cu dispersia s cunoscută; -
tipul
testului: testul z, deoarece volumul eșantionului n ≥ 30 și
repartiția valorilor este normală. Rezolvarea testului
Fig. 2.48 Tabel cu valori ale datelor, indicatorilor
și parametrilor statistici
a b
Fig. 2.49 Scheme
asociate testului: a – varianta ipotezei de nul respinsă; b – varianta
ipotezei de nul acceptată 2.5.5.6.2 Aplicație testul t
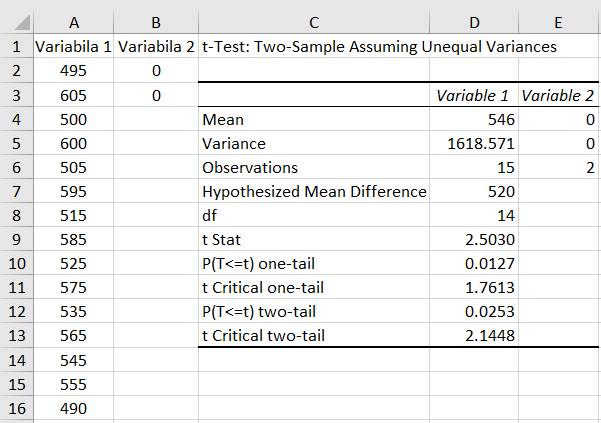
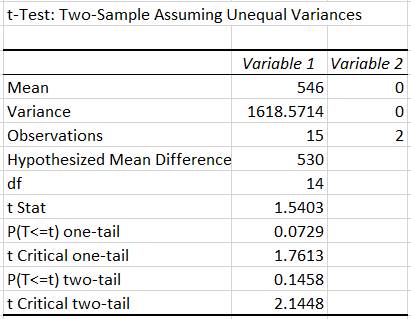
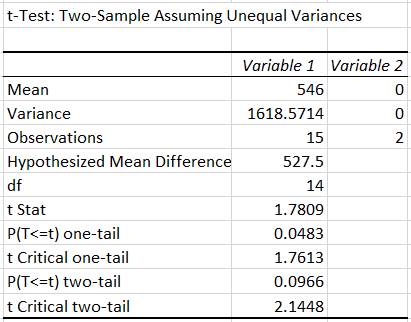
de medie pentru o variabilă Ap.2.12 Să se determine rezistența la rupere R0 la care cedează prin rupere piesele unui lot cu peste 10000 bucăți, cu certitudinea mai mare cu 95%, R > R0 (ipoteza de cercetare), pornind de la un set de măsurători cu n =15 valori, ale tensiunii efective (coloana A, fig. 2.50,a). Se consideră că distribuția valorilor variabilei tensiunii efective nu este normală (Ghid.Ap.2.12). Descrierea problemei statistice: -
definirea
populației: valorile posibile ale rezistenței la rupere ale
pieselor lotului; nu se cunosc parametrii µ, σ; - nivelul de semnificație: α = 0,05 (1%); nivelul de încredere, p = 1-α = 0,95 (95%); -
volumul
eșantionului: n = 15 valori (coloana
A, fig. 2.50,a); -
caractersistica
(proprietatea) de interes, variabila aleatoare: rezistența (tensiunea) la rupere,
R; -
parametrul
de interes; media m cu valoarea de referință R0 (pentru început, se
adoptă pentru R0 o valoare
din prima parte a domeniului a valorilor eșantionului, de ex. R0 = 520 MPa; pentru
valoarea R0 egală cu minimul valorilor (de ex. 505 MPa) procentul
de rezistență la rupere este maxim (spre 100%). -
funcția
statistică: STUDENT; -
tipul
testului: t (STUDENT), deoarece volumul eșantionului n < 30. Rezolvarea testului
a
b c
Fig. 2.50 Tabele cu valori ale datelor: a
– valori măsurători și parametrii testului t cu valoarea de
referință R0 = 520 MPa; b – valori parametrii testului t cu valoarea de
referință, R0 = 530 MPa; c – valori parametrii testului t cu valoarea de
referință, R0 = 527,5 MPa
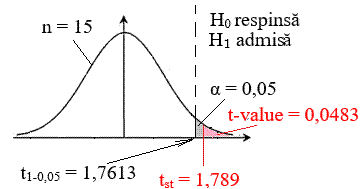
Fig.
2.51 Schemă
asociată testului 2.5.5.6.3 Aplicație t-test de
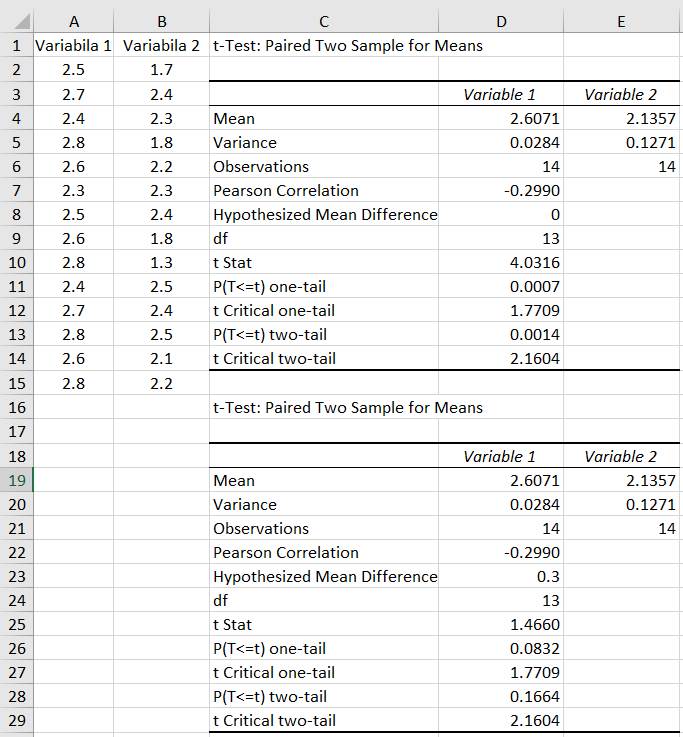
medie pentru două variabile pereche (dependente) Ap.2.13 Să se determine presiunea medie a unui fluid dintr-o conductă prin măsurarea acesteia de către doi operatori, cu același instrument, în puncte diferite și în aceași perioadă de timp. Datele obținute (în urma măsurătorilor), două seturi cu câte 14 valori (coloanele A și B din fig. 2.52), se pot împerechea una câte una (Ghid.Ap.2.13). Descrierea problemei statistice: -
definirea
populației: valorile posibile ale
presiunii din conducă; nu se cunosc parametrii µ, σ; - nivelul de semnificație: α = 0,05 (5%); nivelul de încredere, p = 1-α = 0,95 (95%); -
volumul
eșantioanelor: n = 14 valori fiecare (coloanele
A și B din fig.2.52); -
caractersistica
(proprietatea) de interes, variabila aleatoare: presiunea, p; -
parametrii
de interes: mediile m1, m2;
presiunile pm1, pm2; -
funcția
statistică: STUDENT(t); -
tipul
testului: testul t, deoarece volumul eșantionului n < 30. Rezolvarea testului
Fig. 2.52 Tabel cu valori ale datelor, indicatorilor
și parametrilor statistici
a b Fig.
2.53 Scheme asociate testului: a – varianta
ipotezei de nul respinsă; b
– varianta ipotezei de nul acceptată 2.5.5.6.4 Aplicație t-test de
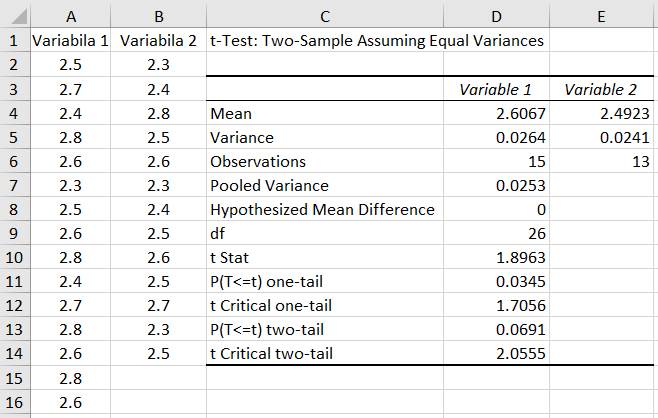
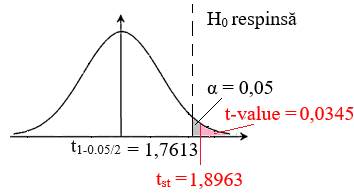
medie pentru două variabile nepereche (independente) cu dispersiile egale Ap.2.14 Presiunea medie a unui fluid dintr-o conductă se poate determina prin măsurarea acesteia de un singur operator, cu același instrument, într-un singur punct de lucru la perioade de timp diferite (de ex. dimineața și seara). Se poate afirma că presiunile medii măsurate sunt aceleași din punct de vedere statistic (ipoteza de cercetare) cu nivelul de semnificație (risc), α = 0,05 ? Datele obținute (în urma măsurătorilor), sunt grupate în două seturi cu câte 15 și 13 valori (coloanele A și, respectiv, B din fig. 2.54); cele două seturi de valori nu se pot împerechea una cate una (Ghid.Ap.2.14). Descrierea problemei statistice: -
definirea
populației: valorile posibile ale
presiunii din conducă; nu se cunosc parametrii µ, σ; - nivelul de semnificație: α = 0,05 (5%); nivelul de încredere, p = 1-α = 0,95 (95%); -
volumul
eșantioanelor: n1 = 15 valori, n2 = 13 valori (coloanele A și B din fig.2.54); -
caractersistica
(proprietatea) de interes, variabila aleatoare: presiunea, p; -
parametrul
de interes; mediile m1, m2; presiunile pm1, pm2; -
funcția
statistică: STUDENT(t); -
tipul
testului: testul t, deoarece volumul eșantionului, n < 30. Rezolvarea testului
Fig. 2.53 Tabel cu valori ale datelor, indicatorilor
și parametrilor statistici
Fig.
2.54 Schemă asociată testului 2.5.5.6.5 Aplicație t-test de
medie pentru două variabile nepereche
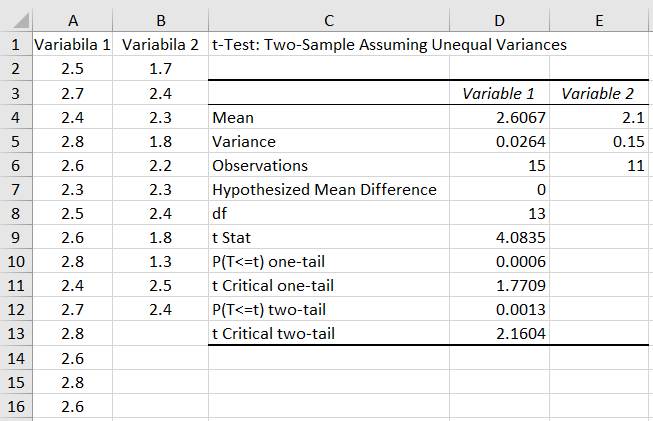
(independente) cu dispersii inegale Ap.2.15 Presiunea medie a unui fluid dintr-o conductă se poate determina prin măsurarea acesteia de doi operatori, cu același instrument, în puncte diferite la perioade de timp diferite (de ex. dimineața și seara). Se poate afirma că presiunile medii măsurate sunt diferite din punct de vedere statistic (ipoteza de cercetare) cu nivelul de semnificație (risc), α = 0,05 ? Datele obținute (în urma măsurătorilor), sunt grupate în două seturi cu câte 15 și 11 valori (coloanele A și, respectiv, B din fig. 2.55), NU se pot împerechea una câte una (Ghid.Ap.2.15). Descrierea problemei statistice: -
definirea
populației: valorile posibile ale
presiunii din conducă; nu se cunosc parametrii µ, σ; - nivelul de semnificație: α = 0,05 (5%); nivelul de încredere, p = 1-α = 0,95 (95%); -
volumul
eșantioanelor: n1 = 15 valori, n2 = 11 valori (coloanele A și B din fig.2.55); -
caractersistica
(proprietatea) de interes, variabila aleatoare: presiunea, p; -
parametrul
de interes; mediile m1, m2; presiunile pm1, pm2; -
funcția
statistică: STUDENT(t); -
tipul
testului: testul t, deoarece volumele eșantioanelor, n < 30. Rezolvarea testului
Fig.
2.55 Tabel cu valori
ale datelor, indicatorilor și parametrilor statistici
Fig.
2.56 Schemă asociată testului 2.5.5.6.6 Aplicație testul F de dispersie pentru două variabile Ap.2.16 Să se verifice că în urma modificării unei instalații
experimentale datele obținute prin măsurători s-au îmbunătățit din
punct de vedere statistic, fiind mai grupate în jurul mediei pentru varianta
îmbunătățită. Astfel, se va compara dispersia setului de date, variabila
1 (coloana A, fig. 2.57), obținute cu instalația experimentală
inițială, cu dispersia setului de date, variabila 2 (coloana B, fig.
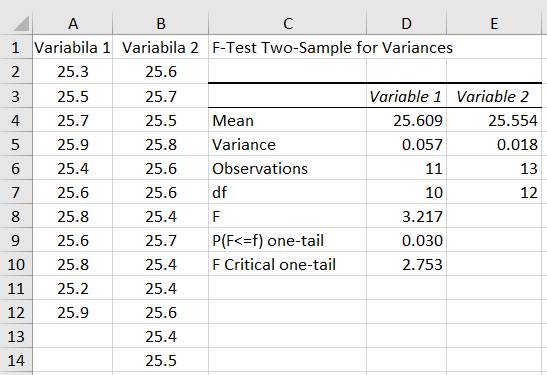
2.57) obținute cu instalația experimentală modificată (Ghid.Ap.2.16). Descrierea problemei statistice: -
definirea
populației: valorile posibile ale
măsurătorilor; nu se cunosc parametrii µ, σ; - nivelul de semnificație: α = 0,05 (5%); nivelul de încredere, p = 1-α = 0,95 (95%); -
volumul
eșantioanelor: n1 = 11 valori, n2 = 13 valori (coloanele A și B din fig.2.57); -
caractersistica
(proprietatea) de interes, variabila aleatoare: valori obținute prin
măsurare, u; -
parametrul
de interes; dispersiile, -
funcția
statistică: FISHER; -
tipul
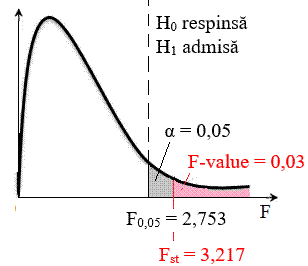
testului: testul F. Rezolvarea testului
Fig.
2.57 Tabel cu valori
ale datelor, indicatorilor și parametrilor statistici
Fig. 2.58 Schemă asociată testului 2.5.5.6.7 Aplicație ANOVA cu un singur factor (one-way ANOVA, Single Factor) ANOVA
este un modul software integrat pachetul Microsoft Excel care detectează diferențele dintre
seturi de date, cu precădere, legate de mediile acestora când există una sau
două variabile dependente parametric și una sau mai multe variabile
independente; ANOVA compară mediile a mai mult de două seturi de date
(variabile aleatorii) spre deosebire de testul t care compară numai două. Tipuri
de module ANOVA: One Way ANOVA (one dependent variable, one independent
variable), Two Way ANOVA (two dependent variable, two ore more independent
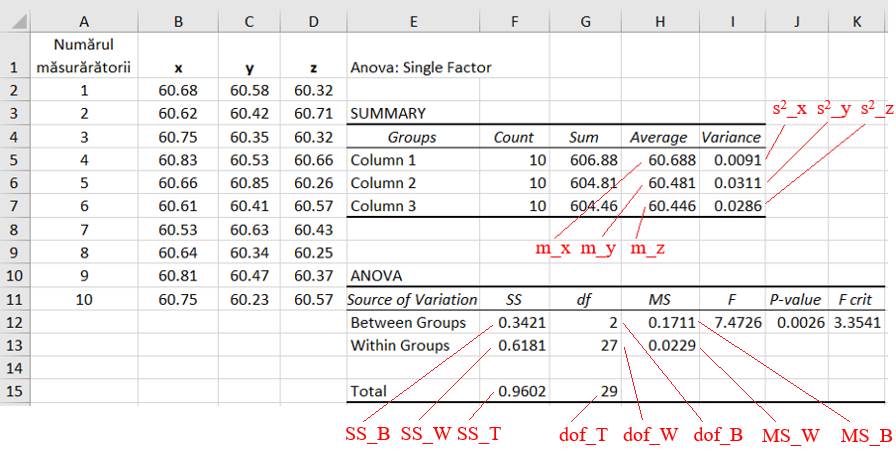
variables) Ap.2.17 Să
se compare statistic seturile de date (x, y, z; coloanele B, C, D din
fig.2.59) asociate măsurătorilor aceluiași parametru fizic oarecare (de
ex. …), dar în condiții de mediu diferite (de ex. la 3 temperaturi diferite) (Ghid.Ap.2.17). Descrierea problemei statistice: -
definirea
populației: valorile posibile ale
măsurătorilor; nu se cunosc parametrii µ, σ; - nivelul de semnificație: α = 0,05 (5%); nivelul de încredere, p = 1-α = 0,95 (95%); -
volumele
eșantioanelor: nx = 9 valori,
ny = 9 valori, nz = 9 valori (coloanele B, C și D din fig.2.59); -
caractersistica
(proprietatea) de interes, variabila aleatoare: valori obținute prin
măsurare, cu distribuție normală (m, s); -
parametrul
de interes: mediile m_x, m_y, m_z; dispersiile s2_x, s2_y, s2_z; -
funcția
statistică: FISCHER; -
tipul
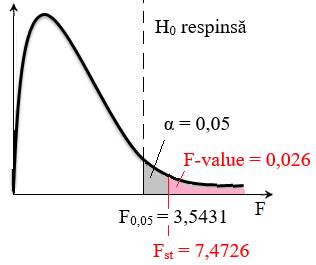
testului: ANOVA. Rezolvarea testului
Fig. 2.59 Tabel cu valori ale datelor, indicatorilor
și parametrilor statistici
Fig. 2.60 Schemă asociată testului 2.5.5.6.8 Aplicație testul ANOVA cu doi factori fără replicație (ANOVA:
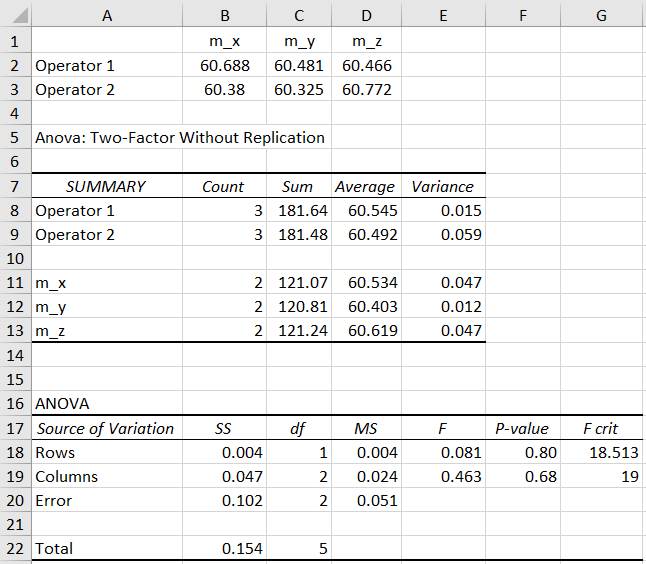
Two-Factor Without Replication) Ap.2.18 Să
se compare statistic seturile de măsurători ale unui parametru fizic
corespunzătoare seturilor (variabilelor) x, y, z cu mediile m_x, m_y, m_z
(coloanele B, C, D din fig.2.61) efectuate de 2 operatori (Operator 1,
Operator 2) dar în condiții de mediu diferite (de ex. x, y, z pot fi
corespunzătoare a trei temperaturi diferite) (Ghid.Ap.2.18). Descrierea problemei statistice: -
definirea
populației: valorile posibile ale
măsurătorilor; nu se cunosc parametrii µ, σ; - nivelul de semnificație: α = 0,05 (5%); nivelul de încredere, p = 1-α = 0,95 (95%); -
volumele
seturilor de medii: m_x, m_y, m_z (coloanele
B, C și D din fig.2.61); -
caractersistica
(proprietatea) de interes, variabila aleatoare: valorile obținute prin
măsurare; -
parametrul
de interes: mediile m_x, m_y, m_z; dispersiile s2_x, s2_y, s2_z; -
funcția
statistică: FISCHER; - tipul testului: ANOVA cu doi factori fără replicație (doi operatori care efectuează 3 seturi de măsurători); implică o singură valoare a fiecărei variabile pentru ce doi factori: operatorii (Oprartor 1, Operator 2) în condiții de mediu diferite cu câte trei valori asociate. Rezolvarea testului
Fig. 2.61 Tabel cu valori ale datelor, indicatorilor
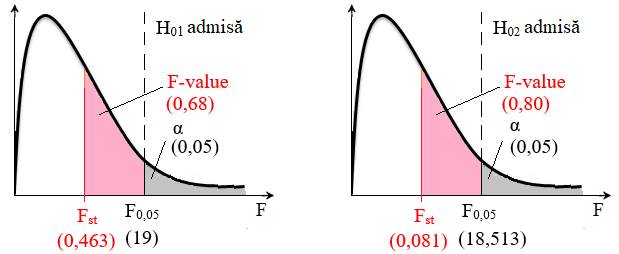
și parametrilor statistici
a b Fig. 2.62 Scheme asociate ANOVA: a – varianta H01 admisă; b – varianta H02 admisă 2.5.5.6.9 Aplicație testul ANOVA cu doi factori cu replicație (ANOVA:
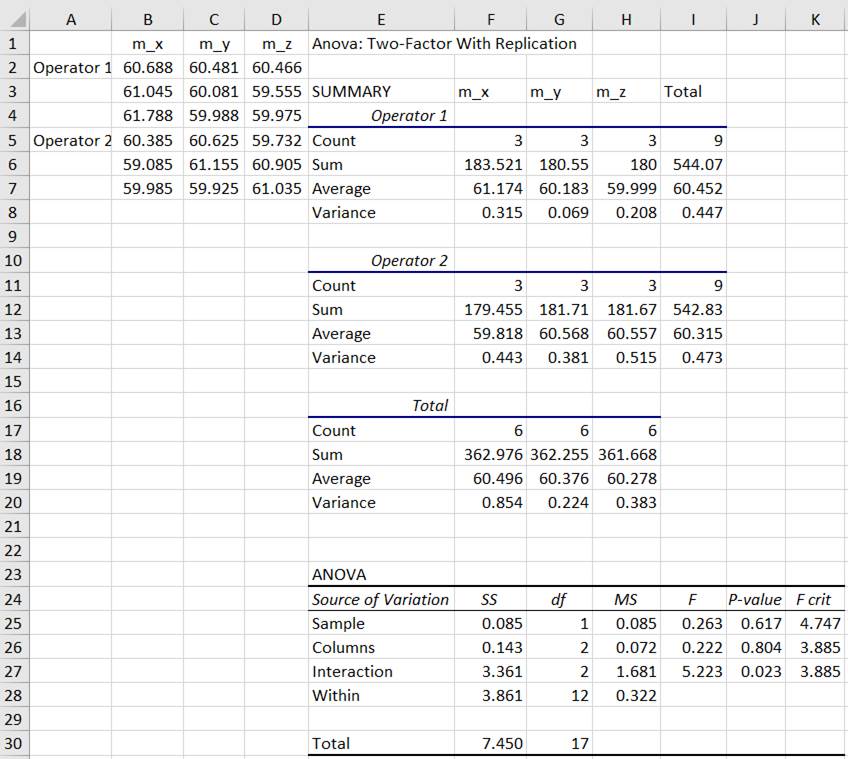
Two-Factor with Replication) Ap.2.19 Să se compare statistic seturile
de măsurători ale unui parametru fizic corespunzătoare seturilor
(variabilelor) x, y, z cu mediile m_x, m_y, m_z (coloanele B, C, D din
fig.2.61) efectuate de 2 operatori (Operator 1, Operator 2) dar în
condiții de mediu diferite (de ex. x, y, z pot fi corespunzătoare a trei
temperaturi diferite) (Ghid.Ap.2.19). Descrierea problemei statistice: -
definirea
populației: valorile posibile ale
măsurătorilor; nu se cunosc parametrii µ, σ; - nivelul de semnificație: α = 0,05 (5%); nivelul de încredere, p = 1-α = 0,95 (95%); -
volumele
seturilor de medii: m_x, m_y, m_z (coloanele
B, C și D din fig.2.61); -
caractersistica
(proprietatea) de interes, variabila aleatoare: valorile obținute prin
măsurare; -
parametrul
de interes: mediile m_x, m_y, m_z; dispersiile s2_x, s2_y, s2_z; -
funcția
statistică: FISCHER; - tipul testului: ANOVA cu doi factori cu replicație (doi operatori care efectuează câte 3 seturi de măsurători); implică câte trei valori ale fiecărei variabile pentru ce doi factori: operatorii (Operator 1, Operator 2) în condiții de mediu diferite cu câte trei valori asociate; există date pereche (replici) prin combinarea celor doi factori. Rezolvarea testului
Fig. 2.63 Tabel cu valori ale datelor, indicatorilor și parametrilor statistici
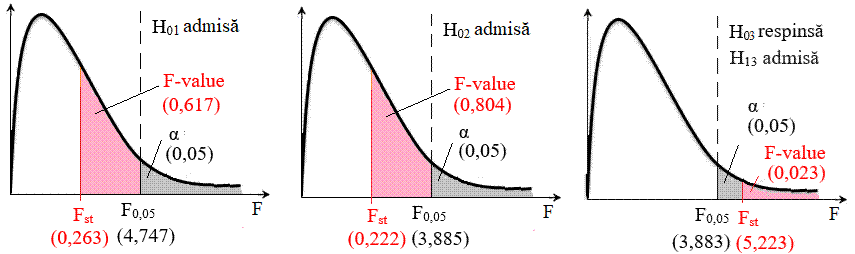
a b
c Fig.
2.64 Scheme asociate ANOVA: a – varianta
H01 admisă; b
– varianta H02
admisă; b – varianta H03 respinsă 2.5.5.7 Analize inferențiale de
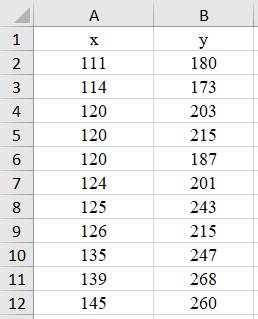
corelare și regresie 2.5.5.7.1 Aplicație de analiza corelației a două variabile Ap.2.20 Să
se analizeze posibilitatea estimării prin regresie liniară a legăturii dintre
variabilele x = {x1,
x2, x3
… x11} și y = {y1, y2, y3
… y11} (coloanele A, B din fig.2.64,a). Se consideră că
variabilele au repartiții normale (Ghid.Ap.2.20).
Descrierea problemei statistice de corelare: -
există
două variabile la nivel de eșantion (număr redus de valori); -
analizele statistice descriptive univariate
evidențiază parametrii statistici principali (ex: mx, my,
sx, sy) și
normalitatea repartiției
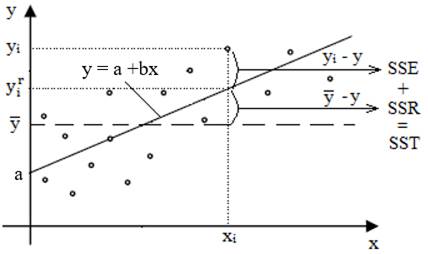
statistice; - pornind de la ipoteza că o anumită valoare a variabilei independente xi, mărime măsurată, yi se supune unei distribuţii normale în jurul valorilor teoretice (estimate) y corespunzătoare celor independente x. Rezolvarea
problemei
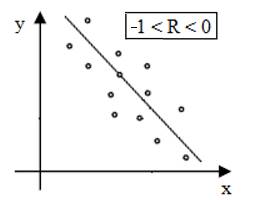
a b Fig. 2.65 Drepte
de regresie: a – crescătoare; b – descrescătoare
2.5.5.7.2 Aplicație de analiza regresiei
liniare simplă Ap.2.21 Să
se analizeze posibilitatea estimării prin regresie liniară a legăturii dintre
variabilele x = {x1,
x2, x3 … x11} și
y = {y1, y2, y3 … y11}
(coloanele A, B din fig.2.71,a). Se consideră că variabilele au
repartiții normale (Ghid.Ap.2.21). Descrierea problemei statistice: -
există
două variabile la nivel de eșantion: dependentă (y) care trebuie
estimată (prezisă) în funcție de variabila independentă (x);
eșantioanele (variabila dependentă, variabila independentă) sunt
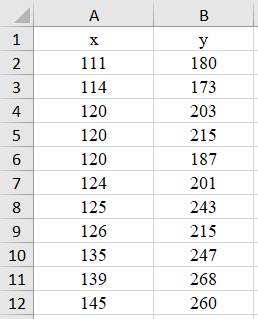
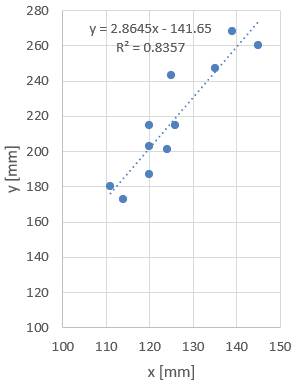
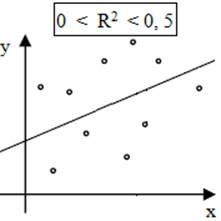
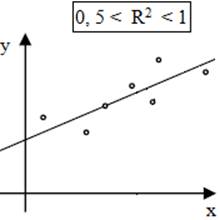
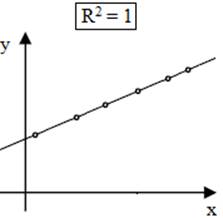
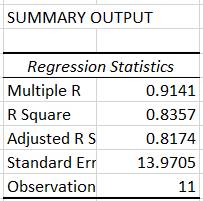
integrabile în populații; - analizele statistice descriptive univariate evidențiază parametrii statistici principali (ex: mx, my, sx, sy) și normalitatea repartiției (statistice); - analiza de corelație indică o valoare a coeficeintului de determinare (R2 = 0,8357; fig. 2.64,b; v. Ap.2.20) căreia îi corespunde acceptabilitatea unei regresii liniare; - se identifică variabila dependentă ca predictor (estimată) și variabila dependentă numită și criteriu; - se pornește de la ipoteza că valorile variabilelor (independentă și depenedentă) au distribuţii normale; -
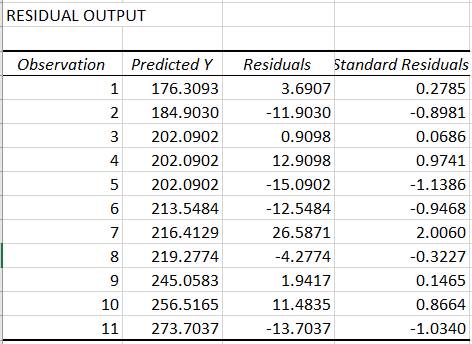
analiza regresie
va indica cât de bine măsurătorile asociate variabilei independente
estimează/prezic valorile variabilei dependente. Rezolvarea
problemei
a
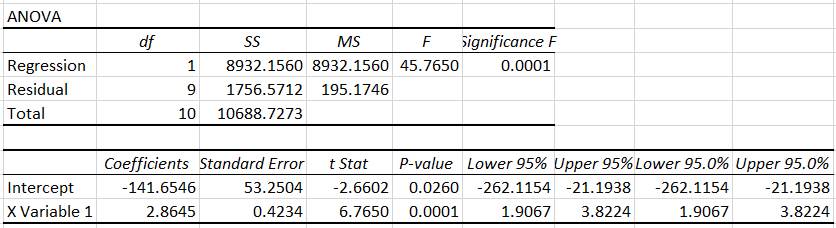
b Fig. 2.67 Valori ale parametrilor statistici: a – tabel cu valori indicatori descriptivi; b – tabel cu valori parametri ANOVA
Fig. 2.68 Dreapta de regresie teoretică cu parametri caracteristici
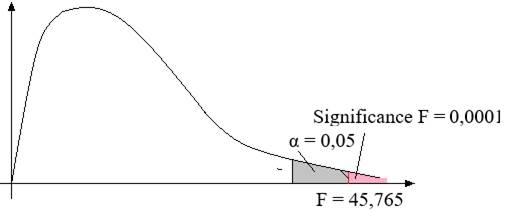
Fig. 2.69 Schema testului Fischer
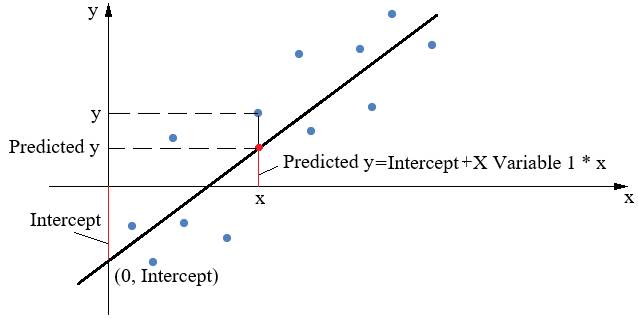
Fig. 2.70 Dreapta de regresie estimată cu parametri caracteristici (Excel)
a b Fig. 2.71 Valori seturi de date și parametri satistici de estimare: a – tabel cu valori variabile; b – tabel cu valori parametri de estimare
Fig.
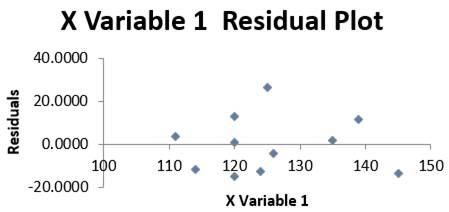
2.72 Graficul erorilor asociate variabilei dependente
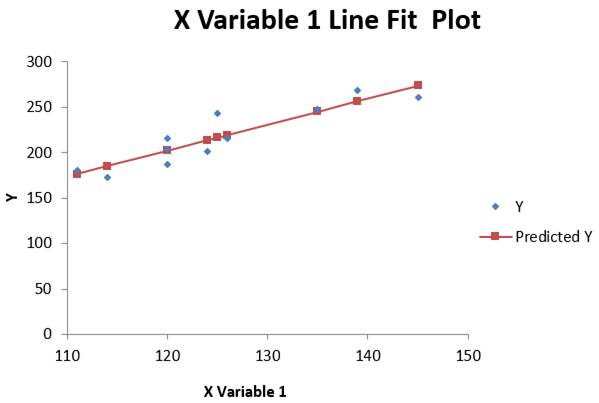
Fig. 2.73 Dreapta de regresie estimată a
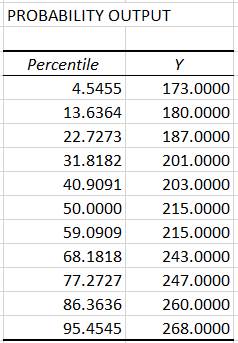
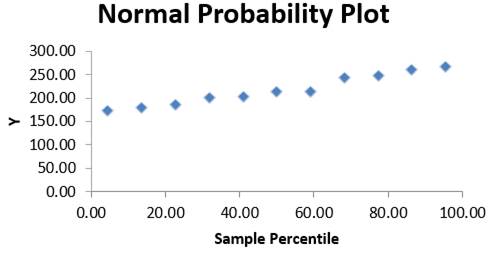
b Fig. 2.74 Valori și grafic de evidențiere a normalității variabilei dependente: a – valori ale probabilităților normale; b – graficul probabilităților normale 2.6 ETAPELE STUDIILOR
(CERCETĂRILOR) EXPERIMENTALE PRIN MĂSURĂTORI 2.6.1 Aspecte
generale Cercetarea experimentală în inginerie este o
metodă științifică care presupune un proces de generare și de
testare (verificare) a unor ipoteze statistice cu scopul de a fundamenta prin
legi un fenomen/proces fizic. Pentru aceasta bazat pe dovezi empirice, de
obicei în inginerie exprimate printr-un număr redus de valori obținute
prin măsurători, se pot lua decizii (concluzii) valabile pentru cazul general
cu o infinitate de valori posibile. Cercetarea experimentală poate fi tratată
ca un proces unifactorial, factorul
(parametrul) studiat se modifică cu considerarea celorlați factori
nemodificați (constanți) sau multifactorial, toți
factorii în fiecare moment sunt luați în considerare. În practică, se întâlnesc,
frecvent, cazuri în care se ia în considerare la măsurare un singur factor.
Având în vedere că cercetările experimentale de laborator legate de organele
de mașini, frecvent, sunt unifactoriale, considerând doar variabilitatea
unui parametru în raport cu alți parametrii considerați invariabili
(constanți), în continuare, se vor face referiri doar la acest tip de
cercetări. Validitatea unui cercetări experimnetale fiind
dată de precizia de descriere a fenomenului fizic care se urmărește a fi
studiat, răspunde la întrebarea: se măsoară cu adevărat ceea ce se
intenționează să se măsoare ?
Deoarece, în inginerie studiile experimentale se realizează pe
eșantioane, în practică, apar amenințări legate de lipsa de
reprezentativitate a acestora, care pot conduce la generalizări a
rezultatelor neconcludente. Pe de altă parte, validitatea rezultatelor unei
cercetări este determinată și de considerarea cu fidelitate a
dependențelor de tip cauză-efect care influențează parametrul
măsurat. Validitatea rezultatelor unei cerectări depinde în mare parte și
de procesul de definire și planificare a etapelor cercetării. Definirea
problemei care urmează a fi investigată presupune un studiu bibliografic în
domeniu, din care să rezulte: ipoteze veridice, modelele robuste,
instrumentele de măsurare adecvate, analiza şi interpretarea datelor
riguroase, prezentarea rezultatelor etc.
2.6.2 Planificarea (proiectarea)
experimentelor unifactoriale 2.6.2.1
Definirea și enunțul
problemei Proiectarea unui experiment deoarece
presupune definirea cu acuratețe a relațiilor cauză-efect are
implicații directe asupra validităţii rezultatelor. Delimitarea domeniului de studiu (ce se cercetează?) presupune, preliminar, studiul biblografic de analiză a nivelul de cunoaștere a fenomenului de studiat, rezultate se urmăresc, posibilitățile de obținerie datelor (se recomandă să adoptarea unei variante mai prin care datele sunt achiziționate (colectate) cât mai rapid și cu costuri cât mai mici). Cercetările experimentale în inginerie bazate pe măsurători, de obicei, sunt cercetări cantitative care bazat pe instrumente statistice stabilesc relații de cauzalitate și/sau testează teorii. 2.6.2.2
Scopul și obiectivele cercetării experimentale Scopul unei cercetări reprezintă intenția generală (viziunea de ansamblu) și rezultatul principal pe care cercetătorul urmărește sale atingă. Obiectivele unei cercetări științifice experimentele se pot referi la descrierea, modelarea și/sau predicția unui fenomen (proces) fizic urmărind: - obţinerea de date, informaţii şi cunoştinţe noi, relevante pentru structura şi funcţionalitatea procesului/fenomenului; - modelarea matematică analitică, empirică sau/şi numerică a dependenţelor care caracterizează procesul/fenomenul de investigat; - simularea şi predicţia stărilor şi evoluţiei specifice. Obiectivele
cercetării experimentale conțin activitățile de realizat pentru a
rezolva problema de cercetare și trebuie să fie în concordanță cu
enunțul problemei atât la nivel general cât și la nivel specificitate.
Obiectivul general al unei cercetări trebuie să includă scopul final
al investigației pentru a dobândi noi cunoștințe folosind
metode și tehnici specifice domeniului problemei. Obiectivele
specifice indică etapele ce trebuie parcurse pentru atingerea
obiectivului principal. 2.6.2.3 Stabilirea
populației țintă (de interes) și a ipotezelor statistice Populaţiile statistice asociate experimentelor cu măsurători se definesc prin totalitatea valorilor posibile ale mărimii măsurate având una sau mai multe caracteristici comune. De obicei, populațiile statistice asociate mărimii măsurate sunt ipotetice și infinite (există un număr foarte mare de valori posibile ale mărimii măsurate). Pentru cunoașterea caracteristicilor unei populații este necesar să se cunoască toate valorile posibile ale mărimii măsurate, fapt care deoarece pentru obținerea acestora ar fi necesare un număr foarte mare de experimente (desigur, în perioade de timp și cu costuri mult mărite), practic este imposibil. Astfel, se poate aprecia carcteristicile populației statistice numai pe baza unei mulțimi finite (eșantion, probă) de valori ale mărimi măsurate inclusă în mulțimea infinită a populației și cu proprietatea ca fiecare element din populație să aibă aceași probabbilitate de a face parte din eșantion. Deoarece, cercetarea bazată pe experimente cu măsurători, este o cercetare de eşantion, se pune problema generalizării observaţiilor obţinute pe un număr limitat de valori, la întreagul domeniu de valori posibile, obţinându-se astfel legi cu aplicare generală. Generalizarea este posibilă aplicând statistica matematică care oferă metode și tehnici științifice de analiză a variabilității valorilor măsurate la nivel de eșantion. Ipotezele statistice au rolul de a descrie în termeni concreţi ce se aşteptă de la studiul urmărit, care, în inginerie, de obicei, este direcționat, pe de-o parte, spre testarea sau verificarea teoriei, și pe de altă parte, spre obținerea unor valori (constante) sau dependențe care ulterior stau la baza modelelor teoretico-experimentale. Ipotezele pot fi enunţuri despre posibile relaţii dintre mai multe variabile dintre care una este dependentă (cea de studiat). În practică, fiecărui fenomen (proces) de studiat i se asociază (cel puţin în mod explicit) un set restrâns de ipoteze. Pentru validitatea cercetării experimentale prin generalizare se va urmări ca în urma măsurătorilor și prelucrării statistice a datelor, nicio ipoteză să nu poată fi invalidată. Modul clasic de testare al ipotezelor statisttice este bazat pe metoda ipotezei nule prin care dacă se demonstrează că între două variabile nu există nicio relație (se infirmară ipoteza nulă) cu un risc impus (de obicei, 5%) se poate concluziona (decide) că ipoteza contrară (alternativă) este validă, între cele două variabile există relație de dependență (de obicei, cu probabilitatea de 95%). Este important să se formuleze ipoteze clare și distincte care să fie verificate înainte de a proceda la colectarea datelor. 2.6.2.4 Determinarea volumului (mărimii)
eșantionului Studiile experimentale, care implică măsuaraea tuturor valorilor parametrului (de obicei, infinite), sunt, de regulă, imposibil de realizat şi se impune constituirea unui eşantion (un set finit de măsurători) care se impune să fie reprezentativ, în raport cu mulţimea totală (populația), comparabil, în raport cu alte eşantioane similare, şi compatibil, în raport cu obiectivele studiului. Volumul necesar al eşantionului exprimat prin numărul valorilor măsuarte ale unui parametru are implicaţii asupra rezultatealor finale (concluzii, generalizări). Astfel, dacă volumul eşantionului este redus, rezultatele obţinute pot fi inprecise, uneori, chiar îndepărtate de cele reale, iar dacă eşantionul este numeros, rezultatatele pot fi precise, cvasiapropiate de cele reale. Altfel spus, eşantionul ca formă de bază a cercetării ştiinţifice bazată pe un număr redus valori obţinute prin măsurători repetate conduce, prin prelucrări statistice, la cunoaşterea populației (mulţimea totală) asociată parametrului măsurat. În practică, din considerente de costuri reduse, studiile statistice consideră eşantioane cu volume mult reduse decât volumul populației (foarte mare sau, deseori, infinit). În literatura de specialitate se evidenţiază mai multe modele de determinare a numărului valorilor măsurate repetitiv (în aceleaşi condiţii). Pentru studiile experimentale în ingineria mecanică se poate folosi modele bazate pe puterea statistică care reprezintă probabilitatea de a obține rezultate semnificative statistic. La planificarea experimentului se impune determinarea volumului minim al eșantionului (numărul minim de măsurători) pentru a obține puterea statistică dorită (1- β), corespunzătoare valorilor unui nivel de semnificație (α) impus și a unui efect estimat (β). Mărimea efectului estimat se stabilește pe baza unor experimente similare, considerate teoretice, sau din documente din literatura de specialitate. Valoarea mărită a puterii statistice (de ex. 0,8) indică că volumul eșantionului conduce la rezultate relevante statistic cu un nivel de semnificație α (de ex. α =0,05) pentru a determina un efectul mai mic decât cel estimat (de ex. β = 0,2), iar dacă puterea statistică are valori reduse (de ex. mai mici ca 0,5) se poate considera că rezultatele nu sunt relevante statistic (valoarea efectului este mai mare decât cel estimat) și în consecință se impune repetarea experimentului pentru un eșantion cu volum mai mare, dacă este posibil practic. Modulul ANOVA din pachetul Microsoft Excel permite analize statistice pentru determinarea acestor parametri atât a priori cât și post-hoc. În ingineria mecanică, uzual, eșantioanele experimentelor cu măsurători au numărul de valori, n = 10…100, dependent de tipurile problemelor și metodelor de analiză statistică. 2.6.3 Realizarea experimentelor, colectarea
şi/sau achiziţia datelor Prin măsurare se atribuire valori numerice unei
caracteristici a fenomenului fizic și se obțin valori ale unei
variabile. Pentru aceasta este nevoie de un instrument (dispozitiv) de
măsurare care să genereze valori numerice cu o unitate de măsură raportate la
un punct de referință (zero). Procesul de măsurare este influențat de
factori perturbatori care, de obicei, au următoarele cauze: principiul sau
metoda de masurare; mijloacele (instrumentele) de măsurare; caracteristicile
mediului ambiant (temperatura,
presiune, umiditate, vibrații etc.); obiectul supus masurării; operator
etc. Astfel, valorile obținute prin măsurare sunt cu erori (v.subcap.2.3.2), dintre care cele aleatorii, de obicei,
se iau în considerare pentru prelucrarea statistică. Aceste erori se
obțin prin repetarea măsurătorilor (în condiții identice). În procesul de pregătire a realizării măsurătorilor se vor analiza sursele de erori; se vor elimina, pe cât posibil, sursele erorilor sistematice şi se vor face evaluări ale erorii aleatorii maximale a rezultatelor pe baza erorilor maximale ale datelor iniţiale. Astfel, se vor analiza influenţele asupra măsurătorilor a diferiţilor factori exteriori (temperatură, presiune, umiditate), iar dacă aceastea sunt semnificative, se va proceda la eliminarea acestora sau la luarea în considerare la prelucrarea datelor şi la determinarea erorilor. 2.6.3.1
Colectarea datelor prin chestionare (online) În inginerie, pentru
variabile calitative, care nu se pot cuantifica numeric, se pot utiliza
chestionare dedicate care pot fi accsate online. Ap.2.22 Să se studieze statistic efectele introducerii la nivelul posturilor de conducere a autoturismelor a unui dispozitiv ADAS (Advanced Driver Assistance Sistem). Deoarece, parametrii de apreciere (confortul și siguranța) sunt calitativi și pentru aceștia nu se pot obține valori prin măsurare, se poate recurge la aprecieri subiective multiple care procesate statistic, deseori, pot da informații cvasifidele despre parametrii analizați. Pentru rezolvarea acestei probleme se propune folosirea aplicației Google Forms (Formulare Google) care prin integrarea în chestionare a răspunsurilor cu aprecieri posibile multiple (Linear Scale), conduce ușor la rezultate fezabile (Ghid.Ap.2.22). 2.6.3.2 Achiziţia automată a datelor Sistemele de achiziție a datelor permit conectarea unui număr
variabil de traductoare și senzori la o unitate centrală de procesare
(calculator) pentru obținere de date numerice pentru prelucrări
ulterioare (fig. 2.75). Traductoarele
au funcţia principală de transformare a unei mărimi neelectrice într-o mărime
electrică. Senzorii pe lângă funcţia principală de transformare a unei mărimi
neelectrice într-o mărime electrică, şi alte funcţii de prelucrare locală a
datelor şi transmitere a lor sub formă de semnale numerice sistemul de
achiziție a datelor sau direct la calculator. Creșterea gradului de
inteligență a senzorilor, în
ultimul timp, a condus la simplificarea sau chiar dispariția sistemelor
de achiziție a datelor, fiind astfel legate hard sau chiar wireless la
calculator. Sistemele de achiziție a datelor sunt structuri, cu
precădăre, electronice care condiționează, amplifică, convertesc digitizează, semnale electrice. Conectarea la calculator a sistemelor de achiziție, de obicei,
se face pein interfețe standard de comunicare serială (RS-232, I2C)
sau paralelă (IEEE 488). Pentru preluarea și prelucrarea semnalelor
direct de la sezori sau prin intermediul sistemelor de achiziție de
date, calculatoarele sunt echipate cu plăci de achiziție.
Sistemele și plăcile de achiziție de sunt asociate cu pachete
software specifice (proprii) sau specializate (LabView, MatLab)
Fig. 2.75 Structura
generală a unui sistem de achiziție automată a datelor 2.6.4 Prelucrarea statistică şi analiza
datelor Procesul de măsurare este influențat de
factori perturbatori care, de obicei, au următoarele cauze legate de:
principiul sau metoda de masurare; mijloacele de masurare; caracteristicile
mediul ambiant (temperatura, presiune,
umiditate, vibratii etc. ); obiectul/procesul/fenomenul supus masurării;
operator etc. Astfel, valorile obținute prin măsurare sunt cu erori (v. subcap.
2.3.2), dintre care cele aleatorii se iau în
considerare pentru prelucrarea statistică. Prin repetarea măsurătorilor (în condiții identice) valorile mărimii obținute xi și implicit valorile erorilor (abaterilor), zi = xi – m, raportate la valoarea adevărată m (media), pentru cazurile experimentelor valide, respectă următoarele poprietăți: valori mici ale abaterilor (erorilor) zi sunt mai frecvente decât valori mai mari; suma algebrică a erorilor zi este nulă; distribuția probabilităților de apariție a erorilor zi, p(z) să fie cât mai apropiată de cea normală (clopotul lui Gauss). Populația statistică se acociază unui număr N mult mărit (tinde la ∞) al valorilor mărimii parametrului măsurat care verifică generalitatea (veridicitatea) modelului teoretic spre deosebire de eșantion care printr-un număr n redus de valori (de obicei, n ≤ 100) estimează mărimea adevărată asociată populației. De obicei, valorile variabilelor asociate mărimilor măsurate sunt evaluate prin intermediul unor parametri statistici de centrare (grupare, localizare): µ (media), pentru populație; m (media), pentru eșantion sau de împrăștiere (dispersie): σ2, pentru populație; s2, pentru eșantion. Obs. De obicei, valorile µ = Datele
numerice procesate de cercetător pot fi, cel mai adesea, rezultatele unor experimente
proprii (măsurate
într-o instalaţie de laborator) sau pot fi preluate (adoptate) din literatura de
specialitate (periodice, enciclopedii, baze de date etc). După colectarea/achiziţia datelor
experimentale, prima activitate ce trebuie desfăşurată este prelucrarea
şi analiza primară, care presupune aplicarea unor metode probabilistice
şi/sau statistice cu scopul verificării consistenţei, corelărilor, precum şi eliminării eventualelor valori
eronate (grosolane, accidentale, sistematice). Ca urmare, uneori, analiza
primară poate impune chiar necesitatea unor determinari experimentale
suplimentare (repetate sau extinse), după care intreaga procedură se reia
pentru noul set de date. 2.6.4.1 Analiza primară a datelor Una din primele etape la analiza primară
presupune identificarea valorilor afectate de erori aberante (grosolane)
care, de obicei, sunt valorile minime sau maxime ale şirului de valori
obținute experimental. Deoarece, aceste valori afectează negativ
analizele statistice se impune eliminarea acestora. Dintre mai multe tehnici de identificare a
valorilor aberante posibile, cea bazată
pe graficul boxplot are un suport ststistic relevant (v.subcap.2.5.4.2). Determinarea
frecvenţelor valorilor unui set de date
obținute prin măsurare, reprezentate tabelar, în vederea analizei
frecvențelor (v.subcap.2.4.5.1) presupune parcurgerea următoarelor etape: -
organizarea
valorilor într-un șir ordonat (coloană sau linie) crescător/descrescător
(considerând, valori distincte); -
gruparea valorilor
în subintervale (grupe, clase) cvasiegale, de obicei, prin divizarea
dimensiunii intervalului, Amp = Max-Min, la numărul de de subintervale,
adoptat apriori (adesea numărul claselor,
cu precădere, în funcție de volumul eșantionului, este 5…15); -
identificarea numărul de apariții
(frecvențe absolute) a fiecărei valori a setului de date în subdomeniile
stabilite și generarea unui șir (linie sau coloană) al
frecvențelor asociat șirului subdomeniilor. -
se calculează frecvențele relative (numărul de valori din fiecare clasă raportat la
numărul total de valori) și sintetizarea tabelar a datelor despre subdomenii, frecvențe
absolute și relative După construirea
tabelului frecvențelor, în general, analiza se continuă cu reprezentarea
grafică sub formă de poligoane și/sau histograme (v.subcap.2.4.5.1). Poligoanele
frecvenţelor se obţin prin reprezentarea de puncte în dreptul mijlocului
fiecărei clase şi unirea acestor puncte prin linii drepte. În plus, la
extremităţi, primul, respectiv ultimul punct corespunde valorii minime,
respectiv maxime din şirul de date. Poligoanele de frecvenţă se utilizează,
mai ales, în cazul când se doreşte compararea a două distribuţii reprezentate
suprapus în acealași grafic. Având în vedere că analizele statisice sunt aplicabile variabilelor aleatorii se impune și veificarea caracterului aleatoriu al datelor (x1, x2… xn) care pentru a fi realizat cu probabilitatea α (coeficientul de încredere) implică respectarea inegalităților (testul Young),
VCI < M < VCS, în care, M = VCI = 0,491 + 0,081n -
De asemenea, în practica analizelor
statistice, în majoritatea cazurilor, se impune veificarea
normalității distribuției (repartiției) valorilor datelor care
de obicei, se poate face vizual, prin analiza graficelor frecvențelor (prin
puncte, histogramă , boxplot etc.) (v.subcap.2.4.5.1), (v. subcap.2.3.2). Dacă graficul obținut are aspect de clopot (simetric cu un singur vârf), rezultatele măsurarilor
se supun unei repartiții Gauss.
Normalitatea
repartiției datelor experimentale se poate aprecia prin evaluarea apropiereii
calitativ și/sau cantitativ de repartiţia normală prin: - compararea graficelor: funcţia de repartiţie a datelor reale trebuie să fie cât mai apropiată de funcţia de repartiţie normală; - compararea abaterii standard a datelor reale cu abaterea standard a repartiţiei normale care are valoarea, 1; - analiza mărimii intervalului de împrăştiere a datelor în jurul mediei; cu cât acest interval este mai mic cu atât datele sunt mai grupate în jurul mediei. - analiza coeficientul de formă care exprimă boltirea (ascuţirea) curbei de repartiţie (v.subcap.2.5.3.4); de obicei, pentru o formă specifică clopotului Gauss acesta are valori apropiate de 3; dacă acest coeficient este mai mare decât 3 atunci curba este mai ascuţită şi datele sunt concentrate în jurul valorii medii spre deosebire de cazurile cu valori mai mici ca 3 care conduc la curbe boltite și datele mai împrăștiate în juril mediei; - analiza coeficientul de asimetrie care exprimă simetria curbei de repartiţie (v.subcap.2.5.3.4); valorile care indică apropiere acceptabilă de repartiția normală sunt în jurul lui 0; dacă acest coeficient este diferit de zero, curba este asimetrică, deplasată spre stânga sau spre dreapta, faţă de curba de repartiţie normală. 2.6.4.2
Prelucrarea statistică și analiza finală Prelucrarea statistică a datelor experimentale (provenite din măsurători), în general, presupune următoarele etape: - determinarea indicatori statistici (v.subcap.2.5.3.1); - analize descriptive (v.subcap.2.5.4) și/sau inferențiale (v.subcap. 2.5.5.6); - estimarea parametrilor populaţiei, - determinarea erorilor de măsurare, - stabilirea preciziei de măsurare etc. Alegerea analizei
descriptive și/sau a testului statistic depinde de natura datelor
și de întrebarea de cercetare care este investigată. Rezultatele
analizei statistice inferențiale vor furniza informații cu privire
la faptul că ipoteza nulă poate fi respinsă în favoarea ipotezei alternative
(care răspunde la întrebarea de cercetare). În cazul măsurărilor indirecte se impune estimarea erorii aleatoare. De exemplu, pentru mărimea necunoscută, y = f(a, b, c …) cu a, b, c … valori măsurate direct, are valoarea medie, my = f (ma, mb, mc …) și abaterea medie pătratică, sy = 2.6.5 Interpretarea
rezultatelor şi elaborarea concluziilor
Spre deosebire de legile fizice deterministe care
guvernează cunoașterea unui fenomen/proces având la bază valori
cunoscute ale unor mărimi la momentul inițial, legile statistice
permit cunoașterea derulării viitoare a fenomenelor/proceselor doar în
termeni probabilistici (probabilități, valori medii, erori statistice
etc.). Scopul interpretării rezultatelor unei cercetări
statistice este de sintetiza concluzii cu referire la fenomenele/procesele
studiate pentru a putea fi integrate la nivel de teorii sau date reprezentative.
Procesul de interpretare a datelor care constă în stabili
sensuri/fundamentări în contexte teoretice generale este diferit de cel de
analiză a datelor care se face în raport cu obiectivele cercetării. O
interpretare riguroasă a rezultatelor cercetării garantează faptul că acestea
sunt legitime și de încredere și că contribuie la dezvoltarea
cunoașterii în domeniul de studiu precizând limitele și
implicațiile potențiale. În subcap. 2.5.4 și 2.5.5. sunt prezentate
aplicații de prelucrarea statistică a datelor, cu precădere
obținute prin măsurări fizice, în care sunt evidențiate și
aspecte de interpretarea rezultatelor |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||